Künstliche Intelligenz (KI) bzw. Artificial Intelligence (AI) ist spätestens seit der Veröffentlichung von ChatGPT in aller Munde. Seit Ende 2022 haben AI-Assistenten Einzug erhalten in große Softwareprodukte wie Adobe Photoshop, Microsoft Visual Studio Code, Office und Windows. Dort sollen diese Assistenten dem Anwender häufige Aufgaben abnehmen, seine Arbeit vereinfachen und damit die Produktivität steigern. Vielen Softwareherstellern stellt sich daher die Frage, ob und wie sie AI-Funktionen auch in ihre Anwendungen integrieren können.
Die eben genannten Beispiele wie Microsofts Copliot oder Generative Fill in Adobe Photoshop sind typische Vertreter der sogenannten generativen AI (GenAI). Sie basieren auf Modellen, die Inhalte wie Bilder und Texte basierend auf Eingaben in menschlicher Sprache erzeugen. Zu dieser Kategorie gehören auch Modelle, die Sprach-, Audio- und Videoinhalte erzeugen können. Sogenannte multimodale Modelle erlauben auch das Mischen von Inhaltstypen.
Der Weg zur KI muss nicht unbedingt in die Cloud führen
Bislang führt der Weg zur Verwendung von GenAI-Modellen praktisch immer in die Cloud: Anbieter wie OpenAI, Microsoft mit den Azure OpenAI Services oder die AI-Funktionen in Google Cloud erlauben die performante Durchführung von KI-Berechnungen auf ihrer leistungsstarken Cloud-Infrastruktur.
Wie immer bei der Verwendung von Clouddiensten bedeutet dies jedoch, dass die Daten an einen anderen Anbieter und vielleicht in eine andere Region übertragen werden. Das kann etwa bei medizinischen Daten oder Geschäftsgeheimnissen problematisch sein. Weiterhin wird eine aktive und stabile Internetverbindung benötigt. Gerade zu Beginn war die Serverkapazität bei den Clouddiensten noch eingeschränkt und durch die Verwendung des Clouddienstes wird man von dessen Schnittstelle abhängig. Schließlich kostet die ausgelagerte Berechnung auch Geld.
Aus diesen Gründen stellt sich die Frage, ob man KI-Modelle auch lokal ausführen kann: Offline, immer verfügbar, ohne die Auslagerung von Daten und ohne, dass es dafür größere Kosten anfallen. Dies wird in diesem Artikel am Beispiel der Chatbots näher betrachtet: Denn mithilfe von WebLLM gibt es ein Softwarepaket, das die komplett lokale Realisierung eines solchen KI-Chatbots erlaubt.
WebLLM: Sprachmodelle für den Browser
Die KI-gestützte Chatbot-Funktionalität wurde durch ChatGPT weltbekannt gemacht. ChatGPT setzt im Hintergrund auf das GPT-Modell (Generative Pre-Trained Transformer) von OpenAI. Dabei handelt es sich um ein sogenanntes Large Language Model (LLM), ein auf vielen Daten trainiertes künstliches neuronales Netz, das Text verarbeiten und generieren kann. Das GPT-Modell ist proprietär, doch es gibt mittlerweile eine Vielzahl alternativer LLMs, etwa das quelloffene Modell LLaMa von Meta AI. Die Besonderheit bei diesen Modellen ist, dass die Schnittstelle menschliche Sprache ist. Auf die Eingabeaufforderung (Prompt) liefert das Modell dann auch eine Antwort in natürlicher Sprache. Das verändert auch die Softwarearchitektur fundamental, die bisher immer auf wohldefinierte Schnittstellen gesetzt hat und führt auch zu ganz anderen Sicherheitsproblemen wie den sogenannten Prompt Injections.
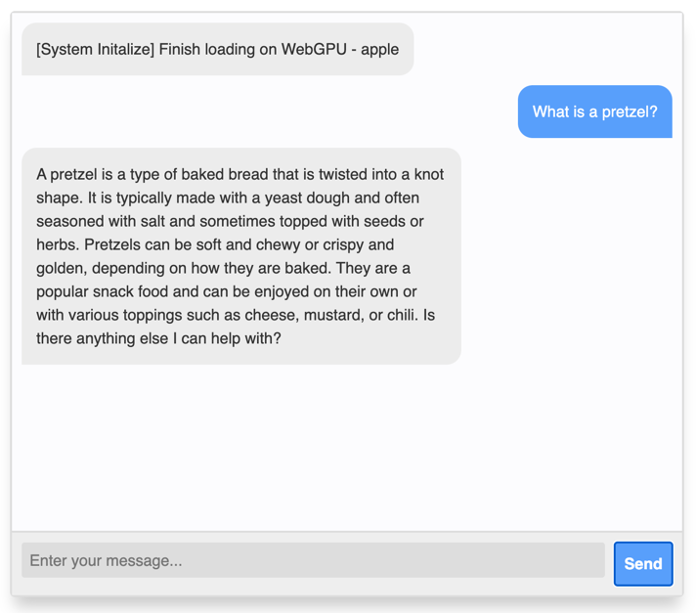
Das Projekt WebLLM von Machine Learning Compilation (MLC) bringt LLMs in den Browser. Der Entwickler hat dabei die Wahl zwischen mehreren Modellen, die lokal ausgeführt werden können. Die Verfügbarkeit und Leistungsfähigkeit der Open-Source-Modelle verbessert sich kontinuierlich, teilweise können es diese Modelle auch mit den meist besseren proprietären Modellen aufnehmen. Standardmäßig wird das oben genannte LLaMa-Model verwendet und im Browser zur Ausführung gebracht. Wie die Abbildung oben zeigt, kann dann direkt im Browser mit dem Chatbot interagiert werden.
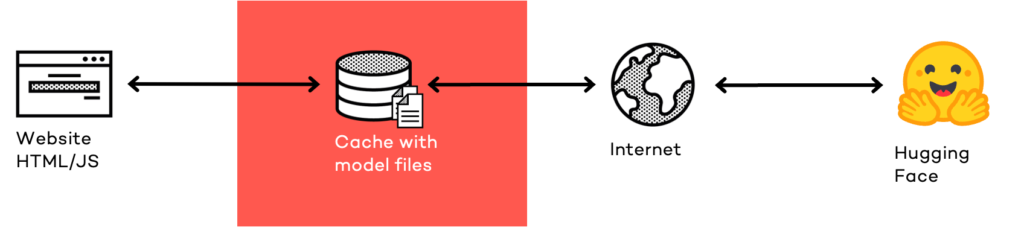
Allerdings muss das Modell dazu zunächst einmal auf das Gerät des Anwenders übertragen werden – und LLM-Modelle sind recht groß. Ihre genaue Dateigröße hängt von der Anzahl interner Parameter (Gewichte) ab. Bei 7 Milliarden Parametern sind LLM-Modelle um die 4 GByte groß, bei 70 Milliarden Paramtern schon rund 40 GByte.
Um das Modell nicht jedes Mal erneut herunterladen zu müssen, kommt eine Technologie zum Einsatz, die im Rahmen der Progressive Web Apps (PWA) im Web eingeführt wurde: Die Cache API. Diese ermöglicht es Entwicklern, HTTP-Requests und -Responses auf dem Gerät des Anwenders zwischenspeichern zu können. Das wird bei PWAs für die HTML-, JavaScript- und CSS-Quelldateien gebraucht, kann aber natürlich auch genutzt werden, um weitere Daten lokal ablegen zu können. WebLLM schreibt die Modellparameter daher in den Cache-Speicher. Ausreichend viel Festplattenspeicher muss dafür natürlich vorhanden sein.
WebGPU erforderlich für performante KI-Berechnungen
Zur Modellausführung selbst kommen mehrere Webtechnologien zum Einsatz: Zum einen WebAssembly (Wasm), ein Bytecode für das Web, der zur Beschleunigung von Modellberechnungen benötigt wird. Für die Berechnungen selbst kommt WebGPU zum Einsatz. Diese Schnittstelle gewährt dem Entwickler Zugriff auf die Graphics Processing Unit (GPU) des Geräts. GPUs sind aufgrund ihrer Auslegung auf parallele Berechnungen für die sogenannte Inferenz besonders gut geeignet, also die Ableitung der Antworten des KI-Modells.
WebGPU ermöglicht die performante Ausführung der KI-Berechnungen im Web also erst. Ohne WebGPU kann WebLLM nicht verwendet werden. Allerdings ist die Schnittstelle derzeit ausschließlich in Chromium-basierten Browsern verfügbar (seit Version 113) und hier auch nur unter Windows und macOS. Unter Linux sowie in Safari für macOS und Firefox muss die API erst durch ein Browser-Flag aktiviert werden.
In der Zukunft könnte die Ausführung von KI-Modellen im Browser noch schneller werden dank der Schnittstelle Web Neural Network (WebNN): Diese erlaubt über CPU und GPU hinaus Zugriff auf die plattformspezifischen KI-Beschleuniger, etwa über die Schnittstellen DirectML auf Windows oder ML Compute auf macOS und iOS. Die Schnittstelle befindet sich derzeit beim W3C in Spezifikation und könnte dann eine nahezu native Ausführungsgeschwindigkeit ermöglichen.
WebLLM in Angular-Anwendungen einbauen
WebLLM steht als einfach verwendbares npm-Paket zur Verfügung (@mlc-ai/web-llm) und lässt sich somit problemlos in eigene Anwendungen einbauen. Das nachstehende Codebeispiel zeigt, wie wenig Code es braucht, um ein LLM lokal auszuführen:
import {ChatModule} from '@mlc-ai/web-llm';
const chatModule = new ChatModule();
await chatModule.reload('Llama-2-7b-chat-hf-q4f32_1');
const prompt = 'What is a pretzel?';
const reply = await chatModule.generate(prompt);Zur Verwendung wird das ChatModule aus dem npm-Paket importiert und instanziiert. Über die reload()-Methode wird zunächst das LLM-Modell geladen, im Beispiel das LLaMa-2-Modell mit 7 Milliarden Parametern (7b). Beim ersten Aufruf müssen daher 4 GByte Daten erst einmal komplett in den lokalen Cache übertragen werden. Wurde das Modell einmal zwischengespeichert, geht eine erneute Initialisierung deutlich schneller und erfordert keine Internetverbindung mehr. Anschließend kann die generate()-Methode mit dem Prompt aufgerufen werden. Das Modell generiert dann eine passende Antwort. Die generate()-Methode nimmt als zweiten Parameter auch noch eine Callback-Funktion entgegen, die mit dem Zwischenergebnis aufgerufen wird. Darüber kann der von ChatGPT bekannte Tipp-Effekt erzielt werden.
Bei der Verwendung des WebLLM-Pakets in Angular muss darauf geachtet werden, dass das dieses intern Abhängigkeiten auf Module enthält, die nur innerhalb der Node.js-Ausführungsumgebung zur Verfügung stehen. Das WebLLM-Paket kann auch in Node.js ausgeführt werden. Es prüft vorher die Ausführungsumgebung und wendet dann die passenden Importe an. Im Browser stehen die Node.js-internen Module allerdings nicht zur Verfügung, weswegen Bundler wie Webpack oder esbuild zunächst streiken, die bei Angular unter der Haube zum Einsatz kommen. Um die Node.js-Module als extern zu markieren und dem Bundler damit zu signalisieren, dass er sich nicht um diese Module sorgen muss, ist folgende Ergänzung in der Datei package.json erforderlich:
"browser": {
"perf_hooks": false,
"url": false
}Zur Laufzeit kann es noch zu Fehlern kommen, wenn die lokal zwischengespeicherte, zum Modell gehörende WebAssembly-Binärdatei nicht mehr zur aktuellen WebLLM-Version passt. Das WebLLM-Team möchte dieses Problem in Zukunft adressieren.
Vor- und Nachteile der lokalen Modellausführung
Dank der lokalen Ausführung von WebLLM werden die oben genannten Ziele erreicht:
- Die eingegebenen Daten verlassen nicht den Browser.
- Das Modell ist immer verfügbar, auch offline.
- Die Antwortlatenz ist nicht abhängig von der Verbindungsqualität oder Serververfügbarkeit.
- Hohe Stabilität, da es keine Abhängigkeit zu bestimmten Modellversionen in der Cloud gibt oder Änderungen der Cloudschnittstelle.
- Geringe Kosten, da der Modelltransfer über Hugging Face erfolgt und die Inferenz auf dem Gerät des Anwenders stattfindet.
Allerdings hat dieser Ansatz auch einige Nachteile:
- Die Antwortqualität kleiner LLMs ist deutlich geringer als die größeren, proprietären Cloud-Modelle.
- WebLLM stellt hohe Anforderungen (RAM, GPU) an das System.
- Die Bandbreitenanforderungen sind aufgrund der Modellgröße von mehreren GByte sehr hoch.
- Es ist nicht möglich, den Cache zwischen mehreren Origins zu teilen, d.h. example.org und example.com müssen beide das 4-GByte-Modell lokal zwischenspeichern.
- Das Laden des Modells ist auch aus dem Cache recht langsam.
- Die Inferenz auf lokalem System ist deutlich langsamer als auf Cloudinfrastruktur und hat einen hohen Energieverbrauch, was bei mobilen Geräten die Batterielaufzeit schmälert.
- Die WebGPU-Schnittstelle wird derzeit nur auf Chromium für Windows und macOS unterstützt, WebNN ist in noch gar keinem Browser verfügbar.
Alternativen: Hybridausführung und spezialisierte Modelle
Als Alternativen kommen auch hybride Ansätze wie die Umschaltung zwischen lokaler Ausführung und der Cloud in Betracht. Ebenso ist es möglich, ein quelloffenes KI-Modell auf unternehmenseigener Infrastruktur bereitzustellen, und damit die Vorteile einer höheren Performance bei gleichzeitiger Datensicherheit zu kombinieren.

Vielleicht muss es aber auch gar kein LLM sein, das als generalisiertes Modell sehr viele Aufgaben übernehmen kann. So gibt es etwa das Projekt Transformers.js, das HuggingFace Transformer direkt im Browser ausführbar macht. Dabei handelt es sich um deutlich spezialisiertere Modelle, die nur eine Aufgabe übernehmen, im Gegenzug aber deutlich kleiner sind. So ist das Übersetzungsmodell t5-small nur rund 80 MByte groß. Allerdings sei auch hier gewarnt, dass die Qualität des Modells nicht mit kommerziellen Modellen wie DeepL konkurrieren kann.
Lokale Ausführung möglich, Cloud meistens interessanter
In diesem Artikel haben wir lokale AI-Funktionen in eine Angular-App eingebaut. Das Beispiel zeigt, dass das grundsätzlich möglich ist. Cloudbasierte Modelle bleiben zumindest derzeit jedoch deutlich leistungsfähiger und sind dank simplem Web-API-Aufruf sogar noch ein bisschen einfacher zu integrieren als WebLLM.
Aufgrund ihrer hohen Dateigröße und Systemanforderungen dürften lokale AI-Modelle nur für sehr spezielle Anwendungsfälle in Frage kommen, etwa bei hohen Anforderungen an die Privatsphäre oder die zwingende Offlineverfügbarkeit). Doch die Leistungsfähigkeit lokaler AI-Modelle sowie die KI-Rechenleistung moderner Geräte steigt stetig und es ist ebenso denkbar, dass eines Tages vielleicht schon das Betriebssystem ein kleines Sprachmodell mitbringt, das dann auch aus dem Webbrowser heraus angesprochen werden könnte.
Auch der Ausblick ist also positiv. Nutzen Sie insofern die Gelegenheit, über einen der gezeigten Wege KI-Funktionen in ihrer App bereitzustellen: leistungsstark und in der Cloud oder auch lokal und offlinefähig.