This is the first article of the series about .NET 7 performance.
- .NET 7 Performance: Introduction and Runtime Optimizations
- .NET 7 Performance: Regular Expressions
- .NET 7 Performance: Reflection (coming soon)
What is performance for us?
Before we look at these performance improvements, we want to take a view from 40.000 feet away of what performance means to us. In most cases, we developers tend to focus on “throughput” performance: How many lines of input can our importer process per second? How many requests can our http API handle in a given amount of time? However, there is also startup performance: How fast can our application start and begin doing its job? If our importer needs 8 seconds to start up and after that, it needs only 2 seconds to process a given file and stop, we might focus on improving the startup time instead of throughput: If we can cut the startup time in half to four seconds – even if that means we need to double the processing time also to four seconds – we are at 8 seconds total instead of 10, and we still are 20% faster overall.
In general, all kinds of performance optimization are often a trade-off: We trade in developer time (analyzing, optimizing) for faster runtime performance. Or we trade in memory consumption to cache data once loaded to prevent later loading roundtrips to other systems. Here, we want to look at how the .NET compilers solve one of these trade-offs in a very elegant way for us:
The optimization dilemma
As mentioned, looking at a piece of code, analyzing it, and trying to optimize it, takes time. Some developers tend to over-optimize their code and spend way too much time on optimizing a method that is called only a few times so that the effort is wasted. Some developers may not optimize their code at all in the first place, and this might create a bottleneck in the so-called “hot path” of the application. The hot path is the code that gets called a lot. So, you ideally write simple code first, and if that piece of code happens to be in the hot path, you might want to spend some additional time analyzing and then optimizing it.
In this article series, we don’t want to look at diverse ways to make our code faster (at least not directly), but we want to dive into how the new .NET 7 can help us. So, let’s move this to our beloved programming environment.
The same optimization dilemma is not only true for us developers but also for our compilers. If you have an application that is compiled into a native executable (i.e. .exe on Windows), you want the compiler to throw all possible optimizations it can provide on the final generated CPU code. This requires some added time at the compile stage but makes the program run faster. So, the compiler trades in compile-time for run-time improvements, which is particularly good for us.
Alas, for us .NET developers, our Roslyn compiler does not directly generate highly optimized CPU-native code but intermediate language (IL) assemblies. The same is true for our Java friends with their Java bytecode. Our IL assemblies need to be compiled to the actual CPU code at runtime. In our case, this is done by the just-in-time (JIT) compiler that is part of the .NET runtime. So, Roslyn is our first-stage compiler (C# to IL), and the JIT compiler does the actual heavy lifting (IL to CPU-native). While the Roslyn compiler can do several optimizations already in the IL code, most of the really impactful optimizations can’t be done at this step. Only when the JIT compiler knows exactly what type of CPU it is targeting (x86, x64, ARM etc.), it can optimize the code to use the most efficient CPU instructions available on the current platform.
The problem with that is this happens at runtime. Our program is already running, and the JIT does its job just in time. So, whatever the compiler does at this stage, it slows down the startup time of our code. Now the JIT compiler has the same optimization dilemma as we developers have: It can take some additional time now, slowing down the program execution, to aggressively optimize a method for the best possible runtime performance. This is great, but if that method is only called once, chances are the compiler spends more time optimizing than the whole method needs to execute. However, if the JIT only does a fast pass and does not apply any optimizations, that method might end up in the hot path, wasting a hell of a lot of CPU cycles because it does not run as efficiently as it possibly could with optimizations.
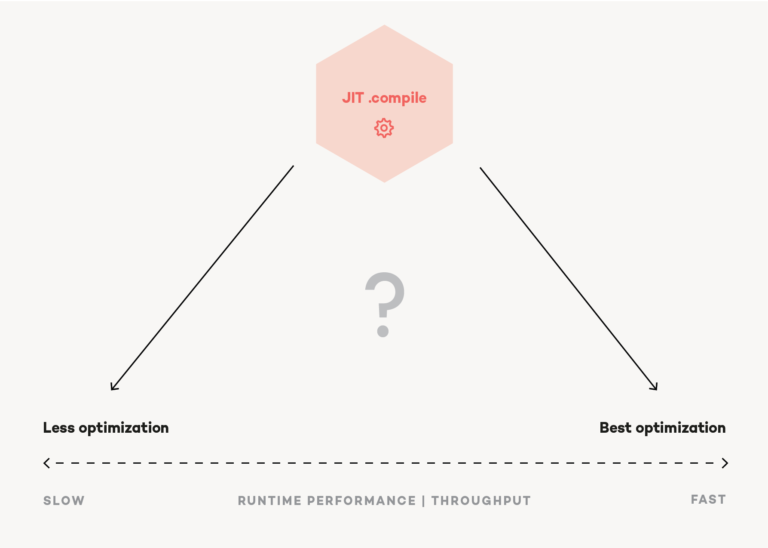
So, our JIT compiler needs to balance initial compilation time (for a faster startup) and applied optimizations (better throughput at runtime). In some cases, this would be an easy decision. An ASP.NET Core service that is started once and runs for hours or days should be optimized as best as possible, even if the startup takes a few seconds longer, while a small console computation tool that is executed once and needs to return fast should startup as fast as possible while optimizations are neglectable. The thing is that our JIT compiler does not know in what scenario it is running.
.NET 7: On-stack-replacement for tiered compilation
To solve this dilemma, the .NET runtime now has some fancy tricks up its sleeve. One of these features is called tiered compilation. This was already available a bit earlier, but we need to know a bit about how this works. The JIT initially only does a fast pass on the methods, without fancy optimizations. But it also adds some lightweight instrumentation code. Using that instrumentation data, the runtime can track how often a method is called. If the runtime detects that a method is called often (based on some threshold or simple heuristics), the JIT compiler is instructed to re-compile the method in question, this time throwing all possible optimization on it. Once this second compilation is completed, the runtime can find all call sites that reference the old (slow) method and patch these to point to the new memory address where the freshly compiled and now highly optimized method code is stored. This is called “tiering up” in the runtime.
This is all great, but we might have our importer tool from above that reads a file in the main method and does heavy computations for each row in that file before it writes it to a database – and since this is a simple tool all the code is in that single loop in the main method. So, there is no method being called a lot of times which the runtime could detect and recompile and replace.
.NET 7 now brings us on-stack-replacement (OSR) to solve this issue. This feature also injects some instrumentation code into loops. It can detect that a loop is in the hot path and is being called often. It then can again instruct the JIT to re-compile the whole main method with all optimizations enabled. After re-compilation, the .NET 7 runtime can capture all registers and local variables on the stack and move that to the very same location within the new compiled method, replacing the current invocation directly on the stack: One iteration of the loop is still slow, and the next is significantly faster.
So, the .NET compiler team did a miracle for us: With OSR and tiered compilation, it can offer us the best startup performance possible by making sure the first JIT compilation is as fast as possible with only a few optimizations. But it also offers us the best possible throughput performance, by individually re-compiling and optimizing the loops and methods that are used often, so that the hot path is optimized as best as possible. And all this while our application is already running.
Conclusion
Performance optimizations are almost always a trade-off between throughput and some other resource: Memory consumption, a hard-working developer or CPU time. Tiered compilation and on-stack-replacement in the .NET 7 runtime provides us with the best of both worlds, as it allows a fast first JIT compilation as well as fast throughput after a somewhat delayed, slower but highly optimized JIT re-compilation. This can make our .NET application faster, just by executing it on the new .NET 7 runtime.
In the next article, we want to explore what .NET 7 has up its sleeves about regular expressions.