The source code for this post can be found here:
https://github.com/thinktecture/feO2x-publishing/tree/datas/2023-08-31_DATAS/Code
TL;DR
Let's start with a benchmark
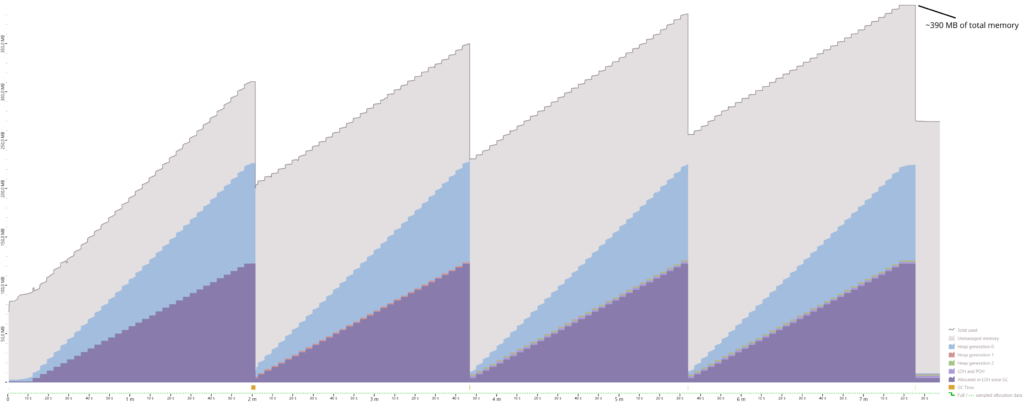
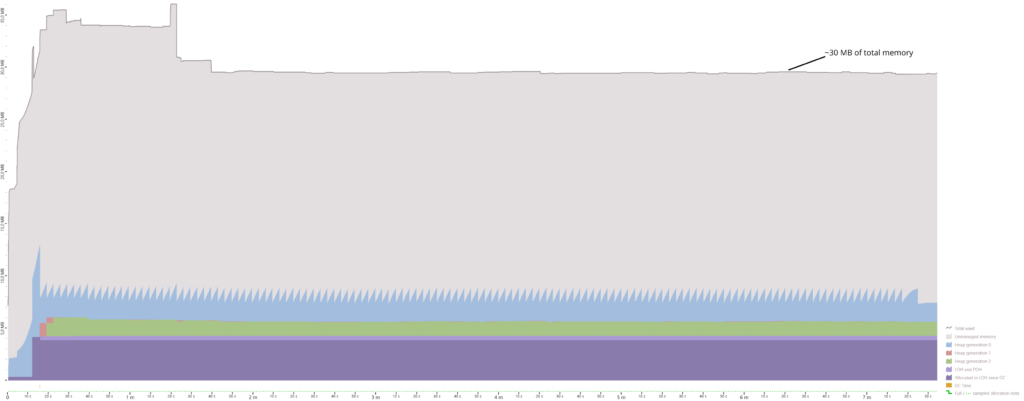
Differences between Server GC mode and Workstation GC mode
- the Small Object Heap (SOH) with its three generations 0, 1, and 2. Objects smaller than 85,000 bytes are allocated here.
- The Large Object Heap (LOH) which is used for objects greater than or equal to 85,000 bytes.
- The Pinned Object Heap (POH) which is mostly used by libraries that perform interop and pin buffers for that (e.g. for networking or other I/O scenarios).
And then along comes DATAS
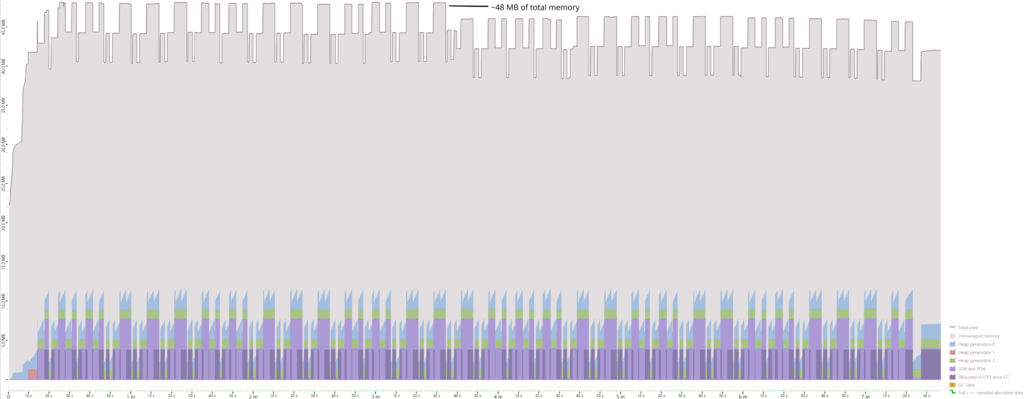
- The GC will start with only a single managed heap.
- Based on a metric called “throughput cost percentage”, the GC will decide whether it is viable to increase the number of managed heaps. This will be evaluated on every third GC run.
- There is also a metric called “space cost” which the GC uses to decide whether the number of managed heaps should be reduced.
- If the GC decides to increase or decrease the number of managed heaps, it will block your threads (similarly to a compacting GC run) and create or remove the managed heap(s). Corresponding memory regions will be moved. The switch from segments to regions in .NET 6 and .NET 7 when it comes to the internal organization of memory within a managed heap makes this scenario possible to implement.
Benefits and drawbacks?
How to try it out
<PropertyGroup>
<ServerGarbageCollection>true</ServerGarbageCollection>
<GarbageCollectionAdaptationMode>1</GarbageCollectionAdaptationMode>
</PropertyGroup>
You can also specify it via command-line arguments when building your project:
dotnet build /p:ServerGarbageCollection=true /p:GarbageCollectionAdaptationMode=1
Or in runtimeconfig.json:
"configProperties": {
"System.GC.Server": true,
"System.GC.DynamicAdaptationMode": 1
}
Or via environment variables:
set DOTNET_gcServer=1
set DOTNET_GCDynamicAdaptationMode=1
Which GC mode will my ASP.NET Core app use by default?
Discussion, Conclusion, and Outlook
In my opinion, DATAS is a great new feature which brings the benefits of Workstation GC and Server GC together: you start out with less memory and when a burst of requests comes in, the GC can dynamically scale its number of managed heaps up to improve throughput. When the number of requests decreases at some later point in time, the number of managed heaps can be decreased, too, to free up memory.
But also, the devil is in the details: when tracing ETW events with PerfView, the reported number of heaps in my benchmarks was always 1 – I will take a look at the official ASP.NET Core benchmarks to see how they traced the exact number of managed heaps. Another important aspect is the decision whether a scale up or scale down is performed: this happens on every third run of the GC, and normally a GC run is only triggered when memory is allocated and the allocation contexts of the threads do not have enough memory left. What if suddenly no allocations are performed (because no requests are incoming)? Will the number of heaps not decrease? And finally, we saw interesting behavior when it comes to the amount of GC runs with DATAS enabled: we could see that they were triggered significantly more often than in regular Server mode – how exactly do the number of GC runs relate to the number of managed heaps?
In the end, DATAS will probably be handled in a similar way to the regions feature: it was introduced in .NET 6, but only activated by default in .NET 7. I would expect that in .NET 8, you have to manually opt in to this feature, while in .NET 9, it might be on by default. We will see what the time brings.
Appendix: About the benchmarks
using System.Threading;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Http;
namespace WebApp;
public static class Endpoint
{
private static ulong _numberOfCalls;
private static int[]? _currentArray;
public static void MapEndpoint(this WebApplication app)
{
app.MapGet(
"/api/call",
() =>
{
var numberOfCalls = Interlocked.Increment(ref _numberOfCalls);
if (numberOfCalls != 0 && numberOfCalls % 1000 == 0)
{
var largeArray = new int[30_000];
Interlocked.Exchange(ref _currentArray, largeArray);
}
return Results.Ok(new NumberOfCallsDto(numberOfCalls));
}
);
}
}
public sealed record NumberOfCallsDto(ulong NumberOfCalls);
using System;
using System.Net.Http;
using NBomber.CSharp;
using NBomber.Http.CSharp;
namespace BomberClient;
public static class Program
{
public static void Main()
{
const int numberOfCallsPerInterval = 300;
var interval = TimeSpan.FromSeconds(1);
using var httpClient = new HttpClient();
var scenario =
Scenario
.Create(
"bomb_web_app",
async _ =>
{
var request = Http.CreateRequest("GET", "http://localhost:5000/api/call");
// ReSharper disable once AccessToDisposedClosure
// HttpClient will not be disposed when this lambda is called
return await Http.Send(httpClient, request);
})
.WithoutWarmUp()
.WithLoadSimulations(
Simulation.RampingInject(numberOfCallsPerInterval, interval, TimeSpan.FromSeconds(20)),
Simulation.Inject(numberOfCallsPerInterval, interval, TimeSpan.FromMinutes(7)),
Simulation.RampingInject(0, interval, TimeSpan.FromSeconds(10))
);
NBomberRunner.RegisterScenarios(scenario).Run();
}
}
- AMD Ryzen 9 5950X, 1 CPU, 32 logical and 16 physical cores
- 64 GB DDR4-3400 RAM Dual Channel 16-16-16-36
- Windows 11 Pro 22621.2134