Article series
- Code sharing of the future
- Better experience through Roslyn Analyzers and Code Fixes
- Testing Source Generators, Roslyn Analyzers and Code Fixes
- Increasing Performance through Harnessing of the Memoization ⬅
- Adapt Code Generation Based on Project Dependencies
- Using 3rd-Party Libraries
- Using Additional Files
- High-Level API – ForAttributeWithMetadataName
- Reduction of resource consumption in IDE
- Configuration
- Logging
More information about the Smart Enums and the source code can be found on GitHub:
- Smart Enums
- Source Code (see commits starting with message “Part 4”)
Please note: When I say performance, then I’m talking about the resource consumption by the Source Generator when running inside an IDE (like JetBrains Rider or Visual Studio), and about the build times of the projects using a Source Generator. This article is not about the performance of the generated code.
I highly recommend reading Part 1, so you know what I’m talking about in this article. You need some basics about Incremental Source Generators before taking the plunge.
New Generator for Testing Purposes
First, we need a new Incremental Source Generator for testing purposes. Create it inside the project DemoSourceGenerator right beside the other generator. The namespace of the generated code is hard-coded to keep it simple and because we won’t have the semantic model in some situations to get the namespace from.
[Generator]
public class PerfTestSourceGenerator : IIncrementalGenerator
{
private static int _counter;
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var classProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) =>
{
return node is ClassDeclarationSyntax;
},
(ctx, _) =>
{
return (ClassDeclarationSyntax)ctx.Node;
});
context.RegisterSourceOutput(classProvider, Generate);
}
private static void Generate(SourceProductionContext ctx, ClassDeclarationSyntax cds)
{
Generate(ctx, cds.Identifier.Text);
}
private static void Generate(SourceProductionContext ctx, string name)
{
var ns = "DemoConsoleApplication";
ctx.AddSource($"{ns}.{name}.perf.cs", $@"//
// Counter: {Interlocked.Increment(ref _counter)}
namespace {ns}
{{
partial class {name}
{{
}}
}}
");
}
}
The generated code prints a static // Counter: <<counter>> to see whether the code has been (re)generated or not.
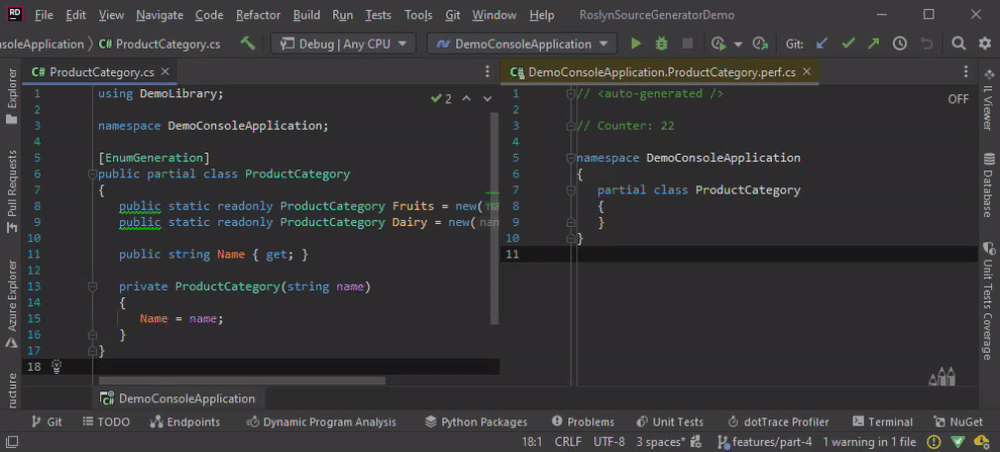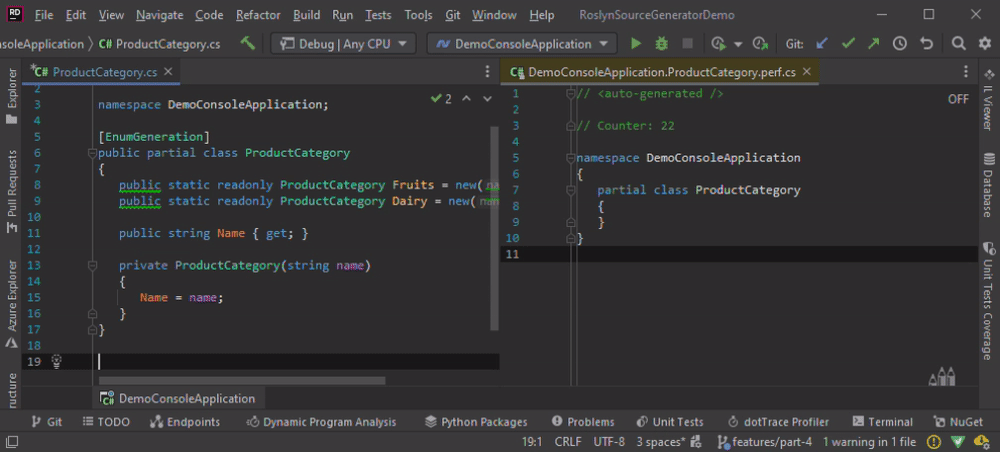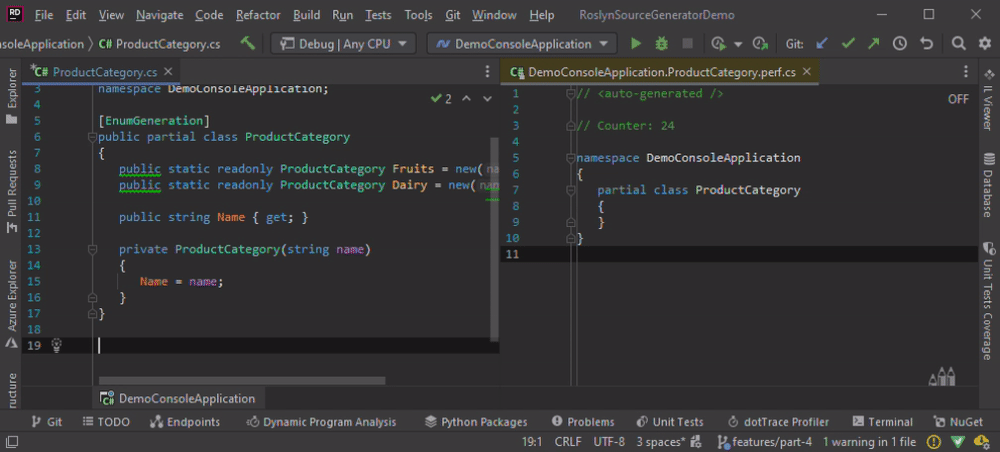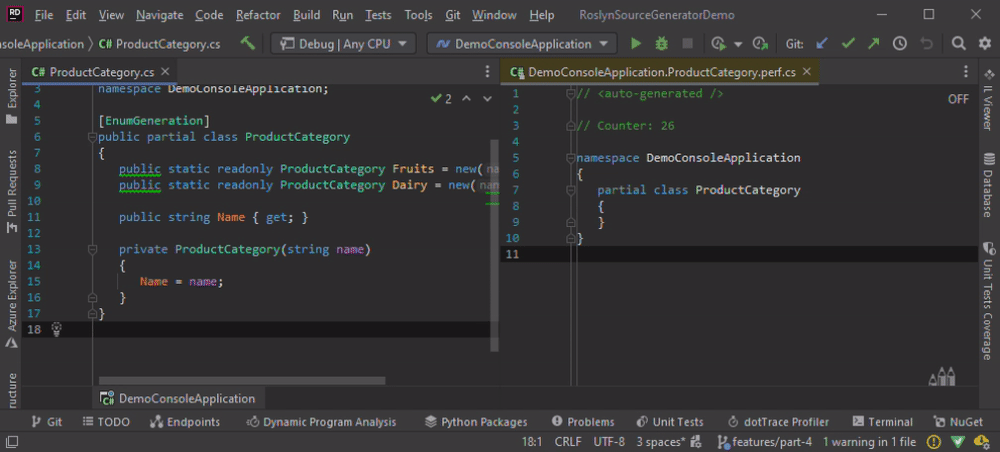
Furthermore, we need another class to see the behavior of the Source Generator when there are more than one relevant type to generate the code for.
using DemoLibrary;
namespace DemoConsoleApplication;
[EnumGeneration]
public partial class OtherSmartEnum
{
public static readonly OtherSmartEnum Item = new();
}
The Predicate
The predicate is the first delegate we pass to CreateSyntaxProvider. As mentioned in Part 1, the predicate should be very fast and filter out as many SyntaxNodes of no interest as possible. This callback is executed on every key-press in the text editor for all nodes of the changed file, i.e. the semantic tree (see animation above).
public class PerfTestSourceGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var classProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) =>
{
return node is ClassDeclarationSyntax;
},
...
Due to the lack of the semantic model in this stage, we are limited to quite simple checks, like:
- The node is a class declaration (
node is ClassDeclarationSyntax), a struct, an interface, etc. - The node is a method (
node is MethodDeclarationSyntax), a property, a field, etc. - The node has at least one attribute (
node is TypeDeclarationSyntax { AttributeLists.Count: > 0 })
For the sake of simplicity, we generate code for all classes.
Tradeoff: Dropping Alias Support for better Performance
Please note: We can gain more performance by dropping support of C# aliases. Every author has to decide for his/her own whether the tradeoff is worth it or not.
If our Source Generator is looking for some specific Attribute, as we did in Part 1, then we can further improve performance by filtering out nodes that don’t have a specific name. For that, we must extract the type name first because the name can be with and without the namespace. Furthermore, the attribute can be with and without the suffix Attribute, i.e. either [EnumGeneration] or [EnumGenerationAttribute].
// The predicate from "Part 1" of the series
private static bool CouldBeEnumerationAsync(
SyntaxNode syntaxNode,
CancellationToken cancellationToken)
{
if (syntaxNode is not AttributeSyntax attribute)
return false;
var name = ExtractName(attribute.Name);
if (name is not ("EnumGeneration" or "EnumGenerationAttribute"))
return false;
...
}
private static string? ExtractName(NameSyntax? name)
{
return name switch
{
SimpleNameSyntax ins => ins.Identifier.Text,
QualifiedNameSyntax qns => qns.Right.Identifier.Text,
_ => null
};
}
With this approach, the predicate will filter out significantly more nodes, but the developers can’t use aliases for the EnumGenerationAttribute anymore. For example, the class below will not be “converted” to a Smart Enum because the alias EnumGen will not be recognized as the EnumGenerationAttribute.
using EnumGen = DemoLibrary.EnumGenerationAttribute;
[EnumGen]
public partial class ProductCategory
{
}
At this point, we should make a risk analysis of “what can happen in the worst case”. In our case, the property Items will be missing, which is noticeable as soon as the developer tries to use it. Unless the property Items is used via reflection, then it is getting ugly… you decide 😊
On the other side, if we decide to not check the name in predicate but to check it later when having the semantic model, i.e. we choose correctness over performance, then we may put a lot of stress on the developer’s machine when the solution is big. Imagine a solution with >10k files and a few dozens of Source Generators, then the IDE may become unresponsive or the code completion (IntelliSense) may break because the IDE will cancel the generation prematurely to save itself.
We are not there yet, but it is something to keep in mind for the future.
Some Thoughts on the CancellationToken
In almost all methods and callbacks provided by the Roslyn API, we have access to the CancellationToken to cancel the execution. In the last stage of the Source Generator, i.e. when generating the actual code, the work can get quite heavy. Especially when generating code for multiple types, we should check the CancellationToken regularly.
If we require a CancellationToken in early stages, like the predicate, which handles one node at a time, then it could be an indication that we have a serious issue. I’m not saying we shouldn’t use the CancellationToken at early stages, but if we do, then we should check whether the code can be optimized, so we don’t require the CancellationToken anymore.
private static void Generate(
SourceProductionContext ctx,
ImmutableArray<ClassDeclarationSyntax> classes)
{
foreach (var cds in classes)
{
ctx.CancellationToken.ThrowIfCancellationRequested();
Generate(ctx, cds, ctx.CancellationToken); // relatively heavy
}
}
In most examples I use the discard operator _ for the CancellationToken because it is not important for our analysis of the IIncrementalGenerator.
The Transformation
The transformation is the second callback we pass to CreateSyntaxProvider and it is the earliest stage we get the semantic model for precise code analysis. The good news is that this callback, unlike the predicate, is not executed on every key-press per se. The bad news: it is executed on every key-press for all nodes that the predicate previously evaluated to true – which may or may not be worse.
Here is an example to make it clear:
We have two files ProductCategory.cs and OtherSmartEnum.cs for which the predicate initially evaluated true. Now, we make a change in OtherSmartEnum.cs, the C# file is parsed, and the predicate is called for all nodes of this one file. The predicate is not called for ProductCategory.cs. After Roslyn is finished calling the predicate, then the transformation is called for both the class declaration of OtherSmartEnum and the class declaration of ProductCategory. Two question may arise at this point: how and why?
- How? – If you wonder where the
ProductCategorycomes from, although it wasn’t parsed in the latest run – the answer is the Roslyn cache. Roslyn keeps track of all nodes the predicate evaluated totrue. The syntax nodes are immutable thus can be easily cached. - Why? – Roslyn doesn’t know whether the newly evaluated syntax node (e.g. class declaration) is somehow interconnected with previously evaluated nodes. For the sake of correctness the transformation is called for all relevant nodes (again).
[Generator]
public class PerfTestSourceGenerator : IIncrementalGenerator
{
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var classProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) =>
...,
(ctx, _) =>
{
var semanticModel = ctx.SemanticModel;
return (ClassDeclarationSyntax)ctx.Node;
});
The transformation itself is a delegate without a concrete return type Func<GeneratorSyntaxContext, CancellationToken, T>, i.e. we can return anything we want. Often I see the Source Generators return either the syntax node itself (ctx.Node) or the ISymbol which comes from the semantic model. On rare occasions, I’ve witnessed generators returning a custom type. Let’s analyze whether the return types matter and if some types should be favored over others.
Return values matter
Both, the transformation and the method Select (see example below) can return an object of any type. For example, the transformation gets the ctx as a parameter and returns the ctx.Node which is passed to the next method Select.
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var classProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) => { ... },
(ctx, _) =>
{
return (ClassDeclarationSyntax)ctx.Node;
})
.Select((node, _) =>
{
return node;
})
Although the API of the IIncrementalGenerator doesn’t dictate the return type, still, some types are handled better by Roslyn than others because there is (hidden) caching after each stage. Better handling means that the code generation is not executed anew, if the corresponding code is not changed.
Syntax Node as Return Value
One of the benefits of the syntax nodes is immutability. A syntax node is only changed if the corresponding file is altered, which qualifies it for caching. One major drawback is that we lose the access to the semantic model unless we combine the pipeline with context.CompilationProvider.
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var classProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) => { ... },
(ctx, _) =>
{
return (ClassDeclarationSyntax)ctx.Node;
})
.Combine(context.CompilationProvider);
// alternatively, combine CompilationProvider with our classProvider
// context.CompilationProvider.Combine(classProvider.Collect());
context.RegisterSourceOutput(classProvider, Generate);
}
private static void Generate(
SourceProductionContext ctx,
(ClassDeclarationSyntax, Compilation) tuple)
{
var (node, compilation) = tuple;
var semanticModel = compilation.GetSemanticModel(node.SyntaxTree);
...
}
The combination with CompilationProvider seems like a good solution at first glance, but it made everything worse. The CompilationProvider fires on every code change in any file, which in return triggers the code generation, i.e. this step undoes everything we’ve been working towards to.
If the Source Generator doesn’t need the semantic model, the syntax node is the easiest way to go without any significant issues.
In the animation below, we change the Program.cs by adding some new lines, which leads to the re-generation of all classes.
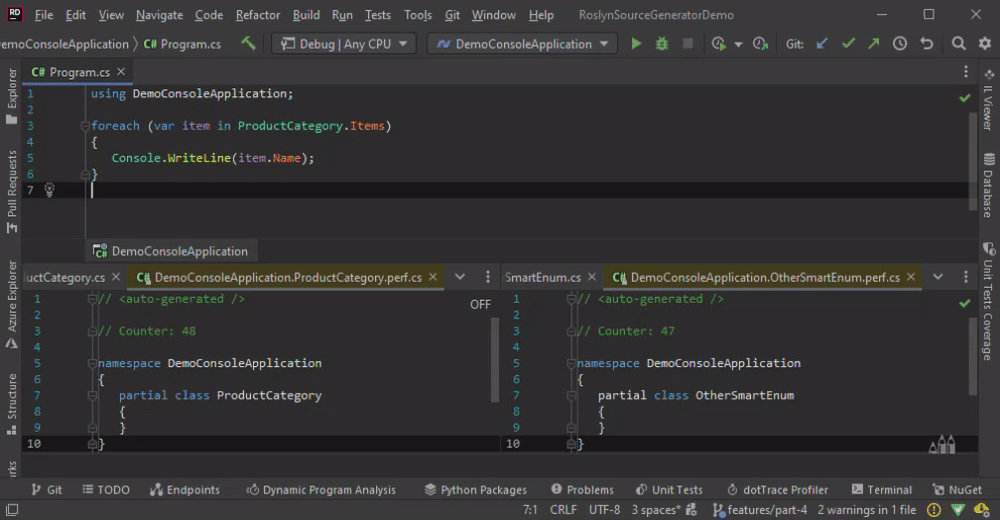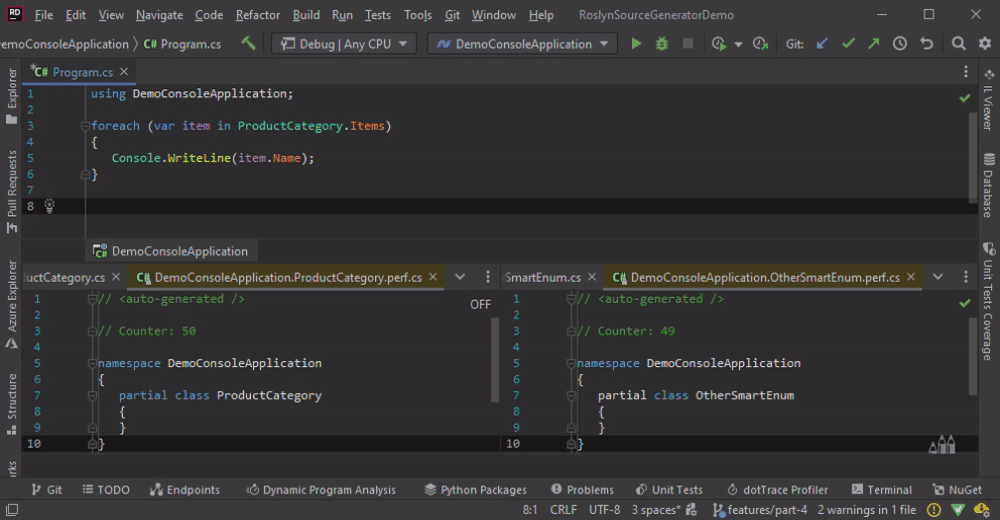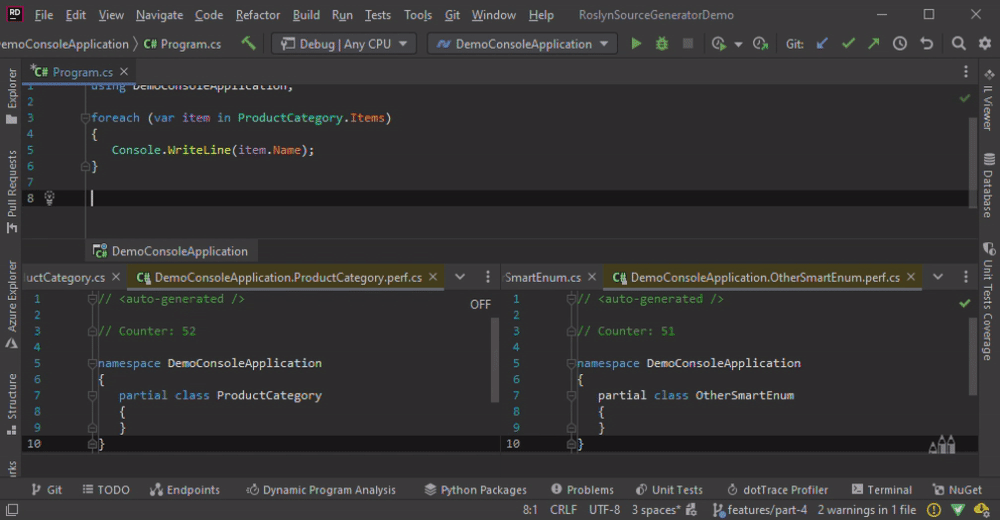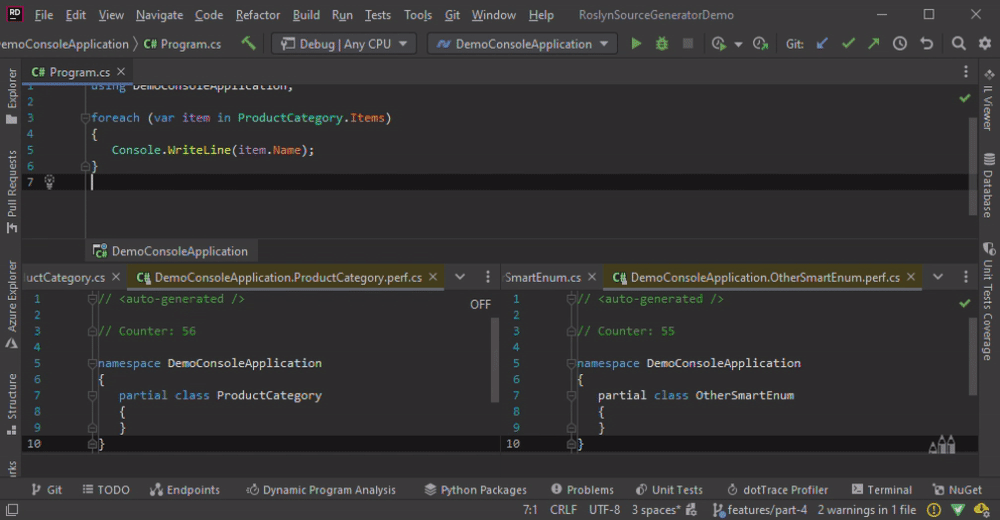
Using a syntax node with the CompilationProvider is not bad per se, but this combination should not be the last operation before RegisterSourceOutput. One option to give the caching a chance to be useful is to add a Select which returns cache-friendly value or to use a custom comparer.
Besides the major issue mentioned above, we have another issue when working with syntax nodes directly. With the current state, if the corresponding file has non-significant changes, like adding a new line, then the Source Generator unnecessarily executes all stages. As with the CompialtionProvider, this issue can be solved with a custom comparer or a cache-friendly return value. I consider this issue as a minor one because (a) we usually need the semantic model and run into major issue first, and (b) if it affects just the file we edit right now, then the impact should be quiet low.
ISymbol as Return Value
The ISymbol can be accessed via the semantic model and provides a lot more information than the syntax node. Alas, the implementations of ISymbol are not very cache-friendly. At least some of the symbols like the implementation(s) of the ITypeSymbol are compared by reference equality. At first glance, this kind of comparison may seem to be suitable for caching, because it works for syntax nodes. But, unlike the syntax nodes, all symbols seem to be recreated (recompiled) on every code change, even if the type and its dependencies didn’t change.
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var classProvider = context.SyntaxProvider
.CreateSyntaxProvider(
(node, _) => node is ClassDeclarationSyntax,
(ctx, _) =>
{
return (ITypeSymbol)ctx.SemanticModel
.GetDeclaredSymbol(ctx.Node);
});
context.RegisterSourceOutput(classProvider, Generate);
}
private static void Generate(SourceProductionContext ctx, ITypeSymbol symbol)
{
Generate(ctx, symbol.Name);
}
When using an ISymbol, we get similar behavior as with the CompialtionProvider. All classes are re-generated on any change of any file. A custom comparer is the best way to fix the issue.
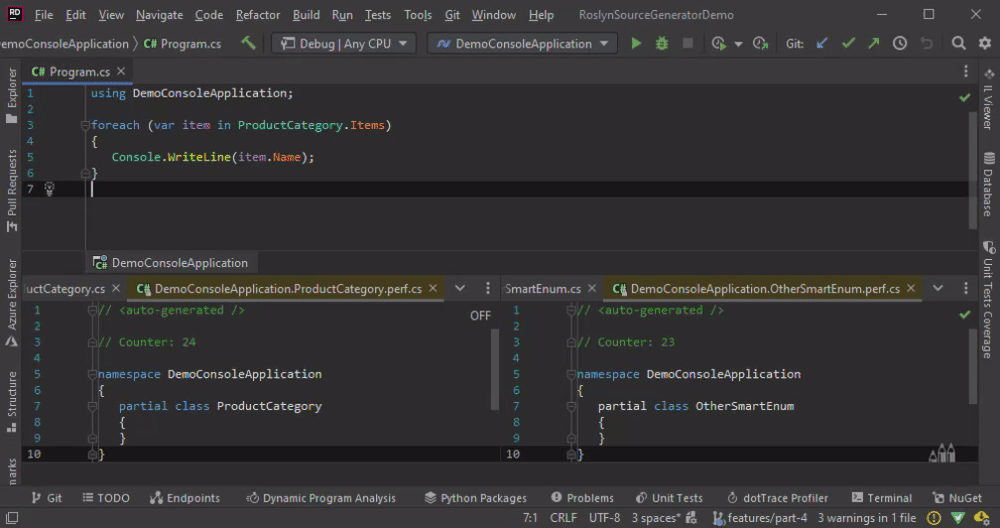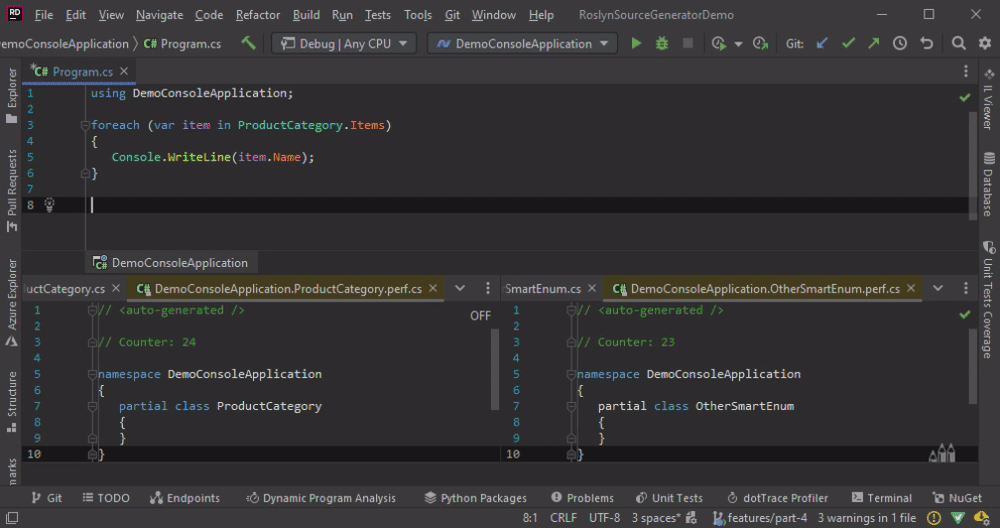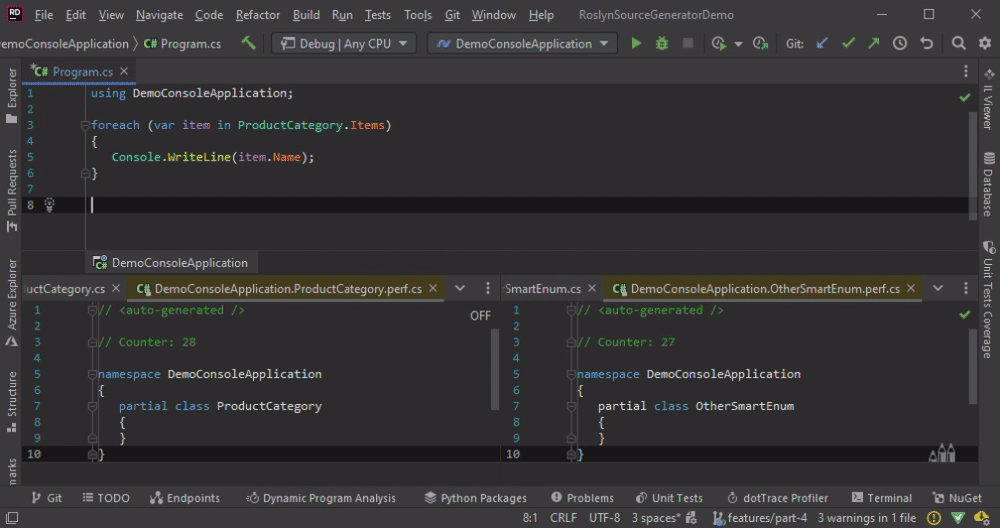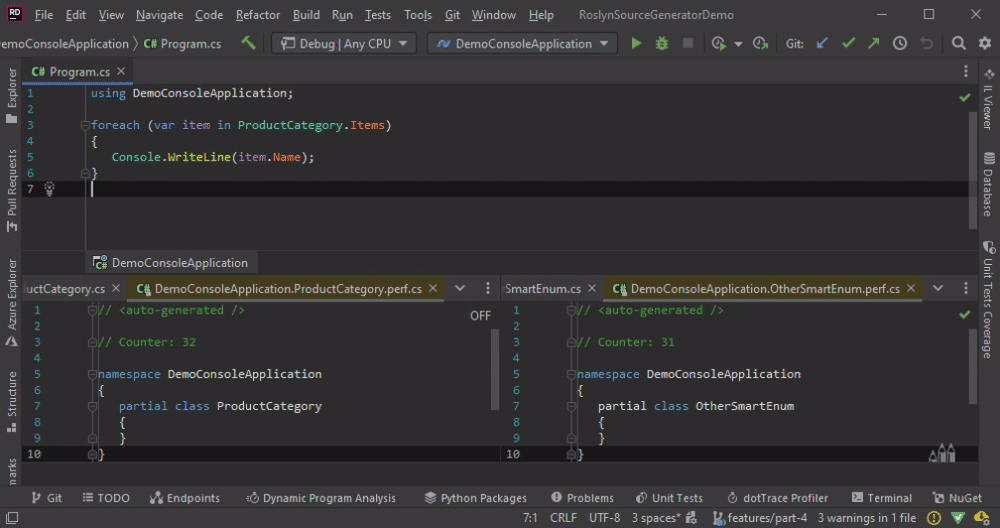
Custom Type as Return Value
With custom types we get better control of what information to pass to the next stage and what to compare. We still can use a custom comparer if we want to, but it shouldn’t be necessary because the type can implement IEquatable directly.
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var classProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) =>
{
return node is ClassDeclarationSyntax;
},
(ctx, _) =>
{
var cds = (ClassDeclarationSyntax)ctx.Node;
return new MyCustomObject(cds.Identifier.Text);
});
context.RegisterSourceOutput(classProvider, Generate);
}
private static void Generate(SourceProductionContext ctx, MyCustomObject myCustomObject)
{
Generate(ctx, myCustomObject.Name);
}
MyCustomObject implements equality comparison which compares the property Name.
public readonly struct MyCustomObject : IEquatable<MyCustomObject>
{
public string Name { get; }
public MyCustomObject(string name)
{
Name = name;
}
public override bool Equals(object? obj)
{
return obj is MyCustomObject customObject
&& Equals(customObject);
}
public bool Equals(MyCustomObject other)
{
return Name == other.Name;
}
public override int GetHashCode()
{
return Name.GetHashCode();
}
}
OtherSmartEnum is not generated anew if we add a new line. The code is generated only then if we change the name. 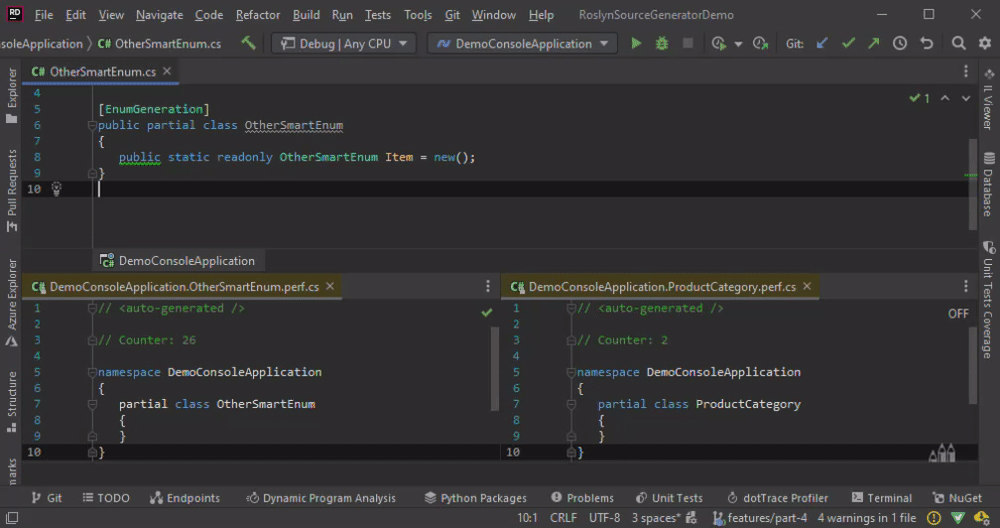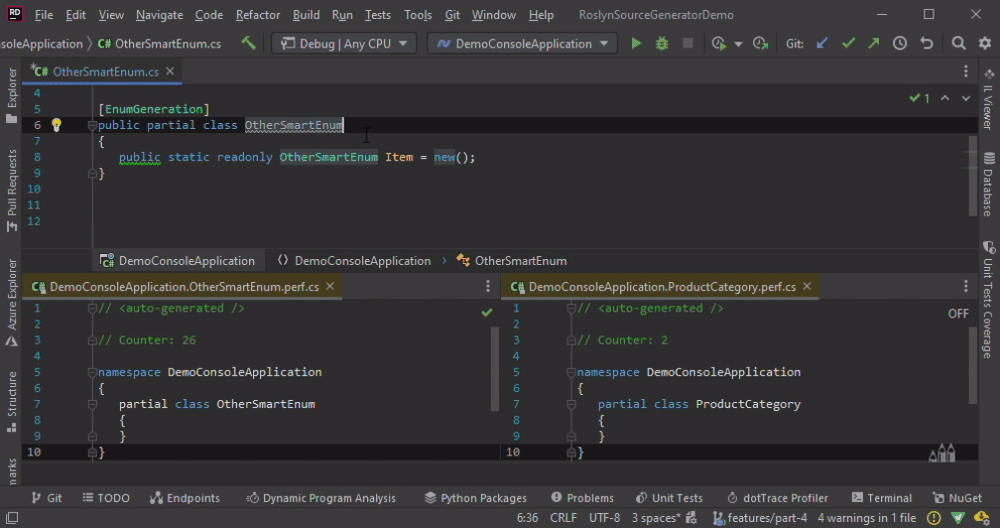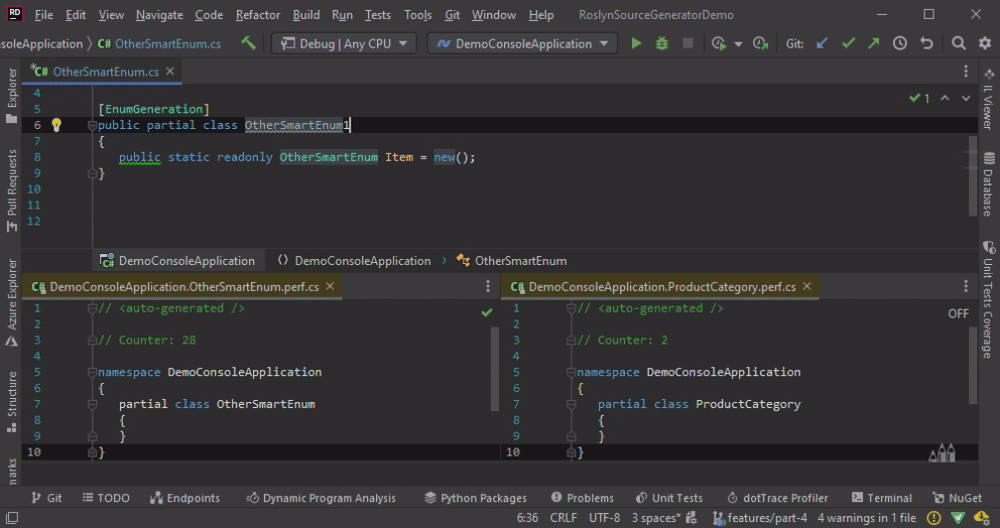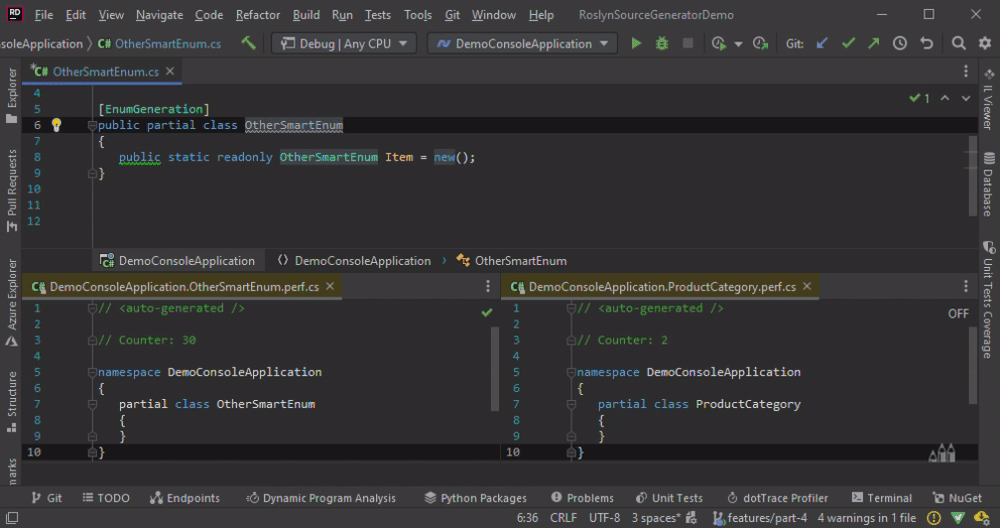
Custom Comparer for Cache-Friendliness
If the return value of the transformation or the method Select is not cache-friendly because the type has unsuitable implementation of the equality comparison then use a custom implementation of IEqualityComparer. An equality comparer teaches the cache whether 2 items are the same or not. If the items are the same then the generated code can be taken from Roslyn cache instead of generating anew.
In the section Syntax Node as Return Value we saw that the combination with the CompilationProvider leads to re-generation of all classes on every code change. This time, we add the MyTupleComparer that compares the class name only.
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var classProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) =>
{
return node is ClassDeclarationSyntax;
},
(ctx, _) =>
{
return (ClassDeclarationSyntax)ctx.Node;
})
.Combine(context.CompilationProvider)
.WithComparer(new MyTupleComparer());
context.RegisterSourceOutput(classProvider, Generate);
}
As with custom types, the IEqualityComparer compares the class name only.
public class MyTupleComparer
: IEqualityComparer<(ClassDeclarationSyntax Node, Compilation compilation)>
{
public bool Equals(
(ClassDeclarationSyntax Node, Compilation compilation) x,
(ClassDeclarationSyntax Node, Compilation compilation) y)
{
return x.Node.Identifier.Text.Equals(y.Node.Identifier.Text);
}
public int GetHashCode((ClassDeclarationSyntax Node, Compilation compilation) obj)
{
return obj.Node.Identifier.Text.GetHashCode();
}
}
With the custom comparer the code is re-generated only if the corresponding class name is changed.
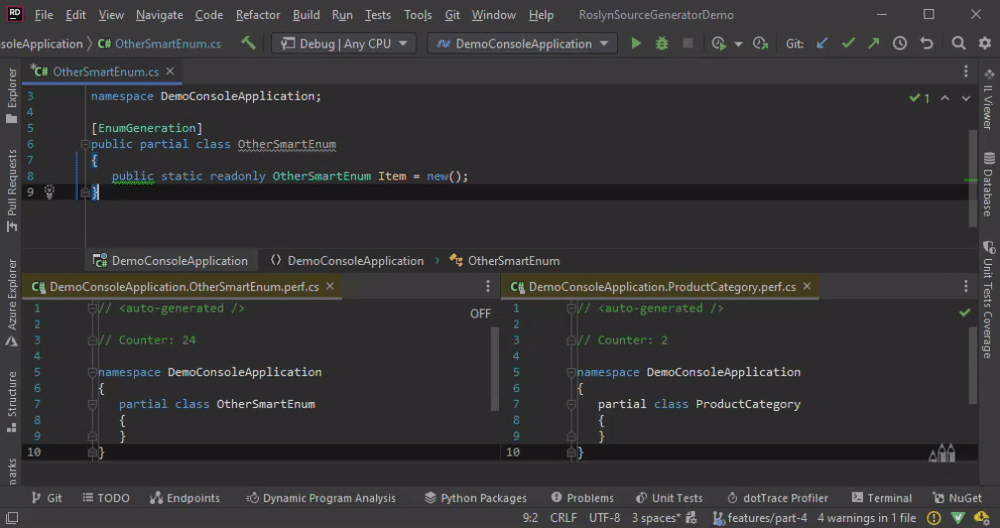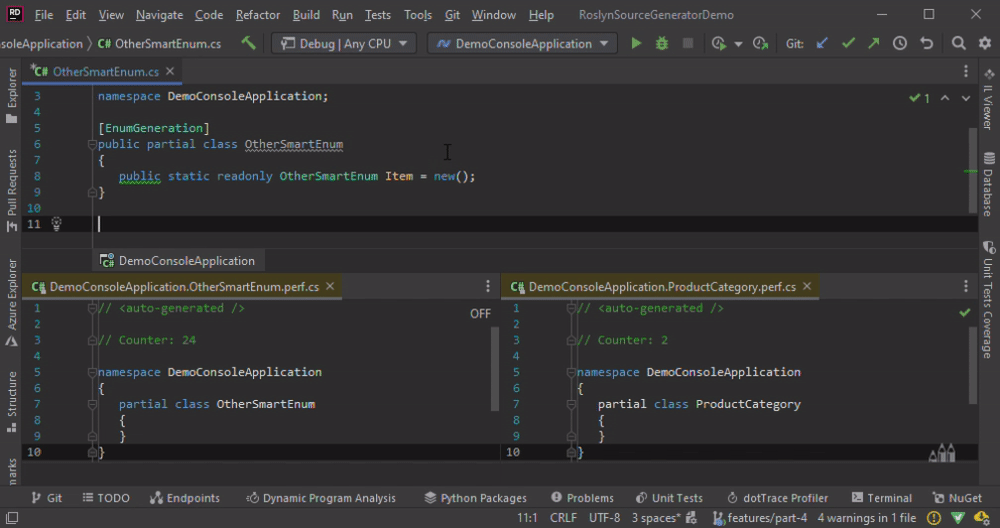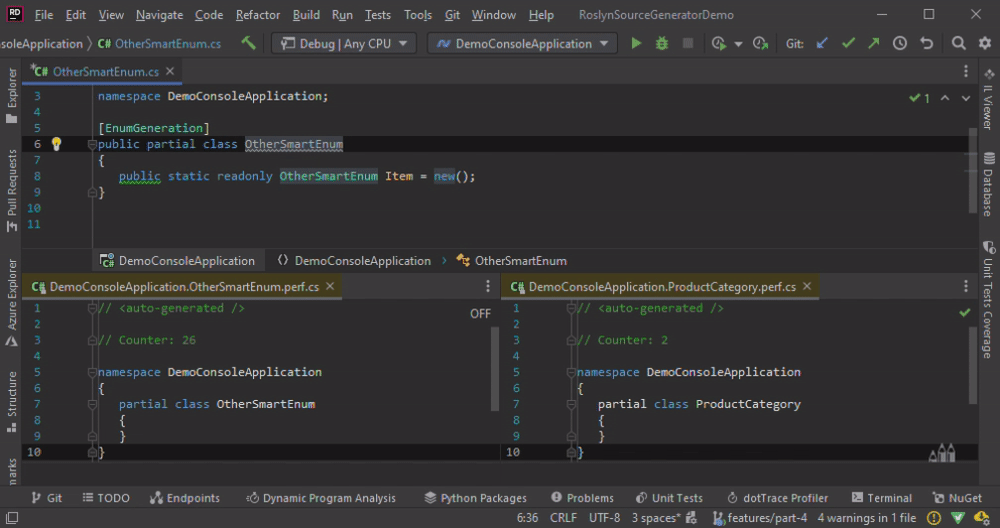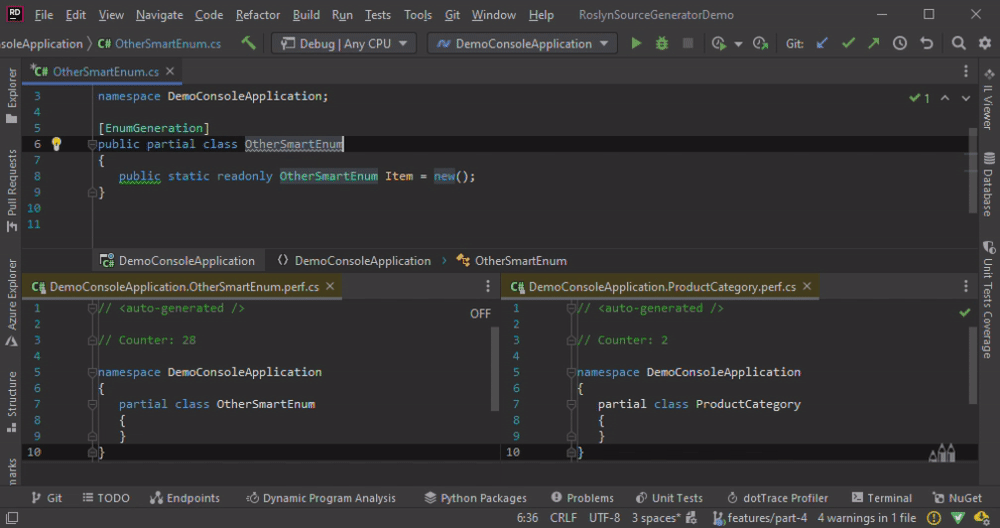
To Collect or not to Collect
By default, the SyntaxProvider emits one syntax node at a time which is filtered, transformed and passed sooner or later to RegisterSourceOutput. Depending on the requirements we may need not one but multiple or all syntax nodes for code generation. But, even if we don’t need all nodes, still, there are some use cases that require the usage of Collect. Let’s analyse what we gain and what we loose with Collect.
At the time of writing this article, it is safer to use Collect because there is an issue (https://github.com/dotnet/roslyn/issues/57991) which breaks the Source Generator.
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var classProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) => { ... },
(ctx, _) => { ... })
.Collect();
context.RegisterSourceOutput(classProvider, Generate);
}
Without Collect
Without Collect every syntax node is handled separately. Although we get better performance that way, there is an issue with this approach. When handling each node separately we may generate multiple (duplicate) files for the same type, if the type consists of multiple partials. Easiest way to reproduce the issue is to copy an existing class like OtherSmartEnum.
[EnumGeneration]
public partial class OtherSmartEnum
{
public static readonly OtherSmartEnum Item = new();
}
public partial class OtherSmartEnum
{
}
As soon as we copy the class, the generator throws internally an ArgumentException with the message The hintName 'DemoConsoleApplication.OtherSmartEnum.perf.cs' of the added source file must be unique within a generator. (Parameter 'hintName'). After the exception, the generator is not participating in code generation inside the IDE anymore, i.e. it’s disabled until restart of the IDE. Depending on the implementation of the Source Generator, the exception may occur when running inside the IDE only but not when building the project or solution. If the exception is thrown on build as well, then it should be seen in the build output.
Generator 'PerfTestSourceGenerator' failed to generate source. It will not contribute to the output and compilation errors may occur as a result. Exception was of type 'ArgumentException' with message 'The hintName 'DemoConsoleApplication.OtherSmartEnum.perf.cs' of the added source file must be unique within a generator. (Parameter 'hintName')
In theory, this issue can be solved by using a random hintName like ctx.AddSource($"{ns}.{name}_{Guid.NewGuid()}.cs", code) but this will make our Source Generator indeterministic. Different names on each code generation will mess up the caching, but, according to my observation, the performance penalties should be minimal. I don’t recommend using any randomness, neither in the generated code nor in the hint names. Ask other developers for some ideas.
With Collect
If the Source Generator requires more than one syntax node for code generation, or for proper handling of multiple partials, then we can use Collect. With Collect the following stages are not getting one item (e.g. a ClassDeclarationSyntax) but all of them.
A typical, but not necessarily best one, implementation uses Collect before passing the result to RegisterSourceOutput. In the method Generate the duplicates are removed by Distinct before generating the code.
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var classProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) =>
{
return node is ClassDeclarationSyntax;
},
(ctx, _) =>
{
var cds = (ClassDeclarationSyntax)ctx.Node;
return new MyCustomObject(cds.Identifier.Text);
})
.Collect();
context.RegisterSourceOutput(classProvider, Generate);
}
private static void Generate(
SourceProductionContext ctx,
ImmutableArray<MyCustomObject> myCustomObjects)
{
foreach (var obj in myCustomObjects.Distinct())
{
ctx.CancellationToken.ThrowIfCancellationRequested();
Generate(ctx, obj.Name);
}
}
The method Collect solves the issue with “duplicate hint names” but introduces another one. The drawback, in terms of performance, are obvious in the animation below. We change the ProductCategory only and the code is re-generated for all classes.
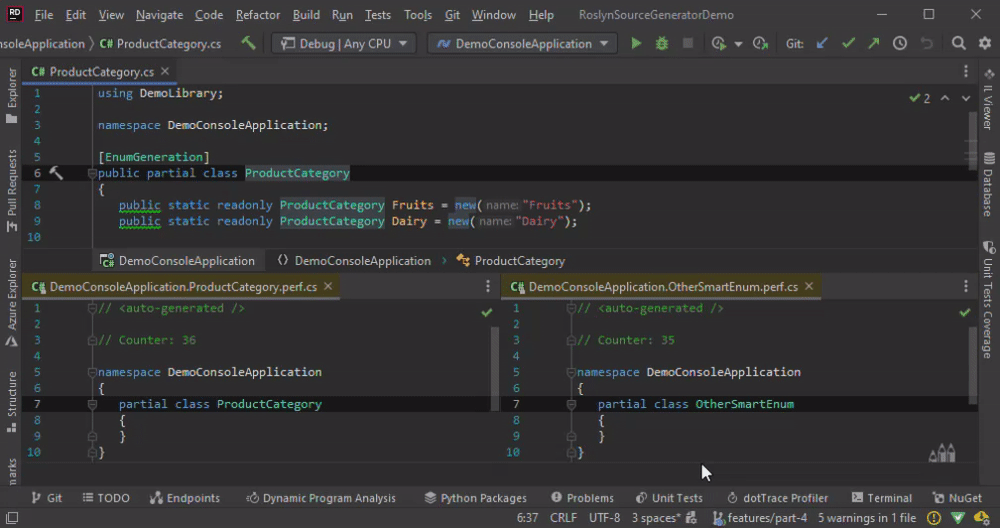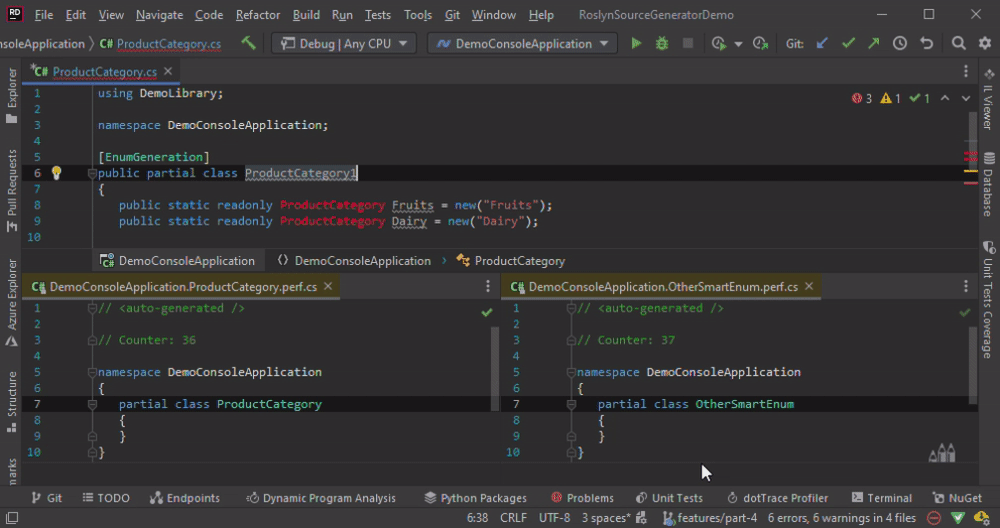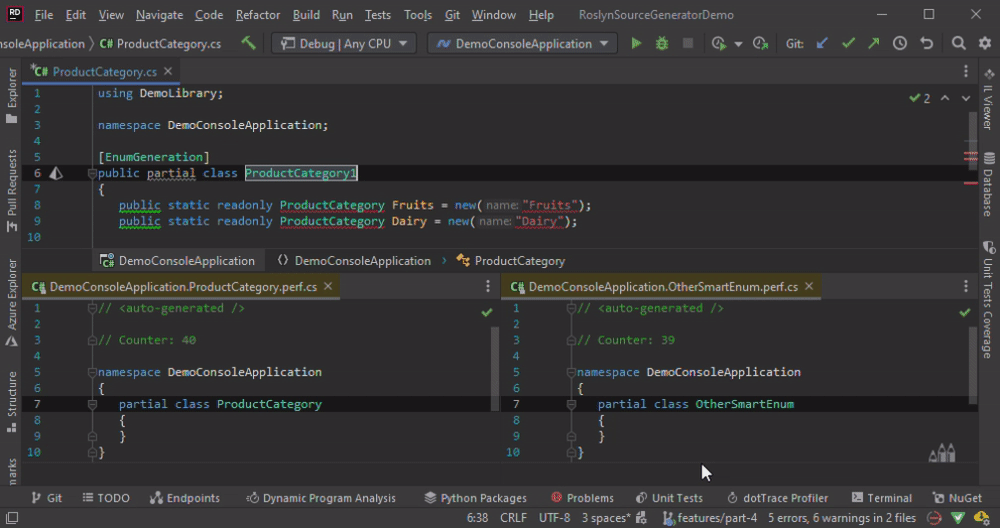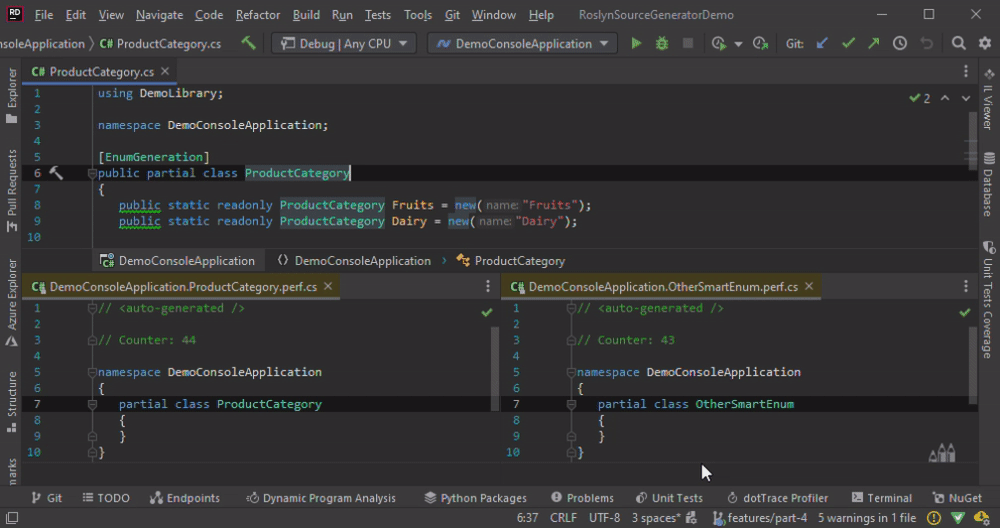
In a nutshell, we don’t want to Collect, but we need it.
How about using Collect and still processing the classes separately?
Building a Pipeline
In the last section we faced a tricky situation. In theorie, our Source Generator doesn’t need the method Collect, but if a class has multiple partials, then we get an error and the Source Generator gets disabled.
Furthermore, there is the pending issue #57991 which makes not-using Collect dangerous. Until we know when and how the issue is going to be resolved, it is safer to use Collect.
One way out of the dilemma is to use the method SelectMany after Collect. With SelectMany we get the items one by one and Distinct removes the duplicates.
public void Initialize(IncrementalGeneratorInitializationContext context)
{
var classProvider = context.SyntaxProvider
.CreateSyntaxProvider((node, _) =>
{
return node is ClassDeclarationSyntax;
},
(ctx, _) =>
{
var cds = (ClassDeclarationSyntax)ctx.Node;
// use the semantic model if necessary
// var model = ctx.SemanticModel.GetDeclaredSymbol(cd);
return new MyCustomObject(cds.Identifier.Text);
})
.Collect()
.SelectMany((myObjects, _) => myObjects.Distinct());
context.RegisterSourceOutput(classProvider, Generate);
}
Adding or removing new lines do not trigger the code generation. New code is generated only then, if the class name changes.
Summary
In this article we looked at some basic methods of the Roslyn Source Generator in detail, how to use them, and what are the implications if not using them properly.
The pipeline at the end of the article is only one approach for building performant Source Generators. I’d like to write about another approaches in the future, but the issue #57991 must be resolved first.