Blazor
Klassische Web-Anwendungen bis hin zu Single-Page Applications
Die ersten Web-Anwendungen, wie sie bereits in der Mitte 90er Jahren aufkamen, waren ausschließlich Server-rendered. Mittels eines Interpreters wie beispielsweise Perl oder PHP wurden die Anfragen des Webbrowsers ausgewertet, und eine neue Antwort-Seite erzeugt, die dann zum Browser geschickt wurde. Für den Browser, und damit den Nutzer, war also jede Operation in der Web-Anwendung mit einem vollständigen neuen Laden der Seite verbunden.

Da das Web als Plattform und das verwendete Protokoll HTTP an sich zustandslos sind, der Sinn und Zweck von Anwendungen aber grundsätzlich immer irgendwie die Darstellung und auch die Veränderung von Zuständen ist, ergab sich hier sehr schnell ein gewisses Problem: Wie (und wo) verwalte ich den Zustand?
Eine damals übliche Variante war das Halten des Zustandes auf dem Server, und zwar meistens im Arbeitsspeicher im Rahmen einer Sitzung. Um den Zustand einer neuen Anfrage des gleichen Browsers wieder zuzuordnen, wird eine ID der Sitzung mittels eines Cookies übertragen. Skalierung war damals meist keine Anforderung, sodass man sich in der Regel mit der Problematik mehrerer Webserver und auf welchem von diesen der Zustand liegt in aller Regel nicht ernsthaft beschäftigen musste.
Als .NET erstmals im Jahre 2002 veröffentlicht wurde, lernten wir eine neue Variante des Zustandsmanagements kennen: ASP.NET WebForms basierte damals, analog zu den bisherigen Desktop-UI-Frameworks, auf Komponenten. Jede Komponente, also jedes Element auf der Webseite, hielt ihren eigenen Zustand. Um diesen zwischen Anfragen beizubehalten, wurde dieser Zustand kurzerhand serialisiert und in unsichtbaren Formular-Elementen übertragen. Dieser sogenannte ViewState führte allerdings sehr schnell zu extrem großen Datenpaketen, die bei jeder Anfrage zwischen Browser und Server übertragen werden mussten, sodass der Server bei jeder Anfrage den letzten Zustand der Seite wieder deserialisieren und auswerten konnte.
Mit der Zeit wurde JavaScript immer mächtiger (und schneller) und so wurde es möglich, immer mehr der Oberflächen-Logik im Browser auszuführen. Damit verschob sich aber auch der Ort, an dem der Zustand benötigt und verarbeitet wurde, vom Server hin zum Client.
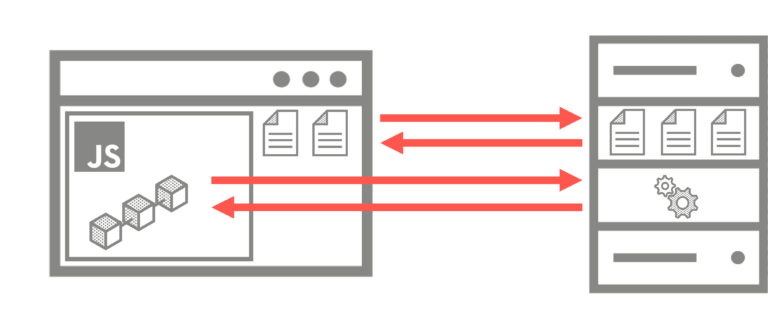
Moderne Single-Page Applications (SPAs), wie sie z.B. mit den Frameworks Angular, React oder Vue erstellt werden, halten nun den Zustand vollkommen innerhalb der JavaScript-Runtime im Browser und sind damit sogar in der Lage, vollständig offline zu arbeiten – sofern bei der Planung und Implementierung der Anwendung darauf geachtet wird, auch wirklich alle dafür notwendigen Daten im Browser vorzuhalten. Sobald sie wieder eine Internetverbindung zum Server haben, können sie ihren Zustand mittels Anfragen an den Server synchronisieren. Aufseiten des Servers muss dazu eine Web-API bereitgestellt werden, mit der die Single-Page Application kommunizieren kann.
Egal, welches Framework man für die Entwicklung einer Single-Page Application einsetzt, es wird immer eine Gemeinsamkeit geben: Der Code, der am Ende im Browser des Clients läuft, besteht grundsätzlich aus JavaScript. Also, auch wenn man seine APIs für das Backend mit C# schreibt, muss für das Frontend JavaScript oder z.B. TypeScript verwendet werden. Es gibt hier also einen signifikanten Technologiebruch zwischen Client und Server.
Blazor ist eine Technologiefamilie von Microsoft, die diesen Technologiebruch entschärft, weil hier die überwiegenden Teile des Frontends ebenfalls in C# programmiert werden können. C#-Entwickler können daher – abhängig von Struktur und Architektur ihres existierenden Projektcodes – Teile von bereits vorhandenem C#-Code in ein Blazor-Projekt übernehmen. Gleichzeitig ist die Lernkurve bei Blazor für C#-Entwickler nicht so steil wie bei den JavaScript-basierenden Frameworks. Der Entwickler ist in der Lage, viel bereits bekanntes Wissen über .NET, C# und Razor auch in Blazor anzuwenden.
Für viele Teams mit umfangreichen C#-Anwendungen eröffnet sich hier also ein interessanter Weg in die Webwelt, der weniger radikal als die verbreiteten JavaScript-basierten Ansätze daherkommt. Schauen wir uns in den nächsten beiden Kapiteln daher einmal genauer an, warum es Blazor in zwei Geschmacksrichtungen als Blazor WebAssembly und als Blazor Server gibt.
Kostenloses Whitepaper: ASP.NET Core Blazor WebAssembly
Christian Weyer hat zum Thema “ASP.NET Core Blazor WebAssembly – das SPA-Framework für .NET-Entwickler?” ein Whitepaper erstellt, in dem er alles Wissenswerte zusammengefasst hat.
Melden Sie sich kostenlos zu unserem Newsletter an, um das Whitepaper per E-Mail zu erhalten.

Blazor WebAssembly
Blazor WebAssembly adaptiert sehr stark die Architekturüberlegungen und Denkmuster der etablierten Single-Page Application Frameworks. Der Unterschied von Blazor WebAssembly zu einer JavaScript-basierten SPA besteht hauptsächlich darin, dass tatsächlich unser .NET Code im Browser ausgeführt wird. Dies geschieht unter Verwendung des WebAssembly-Standards in einem mehrstufigen Prozess.
Hinweis: Der Browser unseres Benutzers muss dazu echte .NET IL Assemblies, also klassische binäre .dll-Dateien, von unserem Webserver herunterladen. Das ist allerdings etwas, das viele Firewalls, insbesondere die etwas restriktiveren im Unternehmensumfeld, nur zu gerne aktiv unterbinden: Der Download von ausführbaren Dateien kann daher blockiert sein – und damit ist unsere Blazor WebAssembly Anwendung nicht ausführbar.
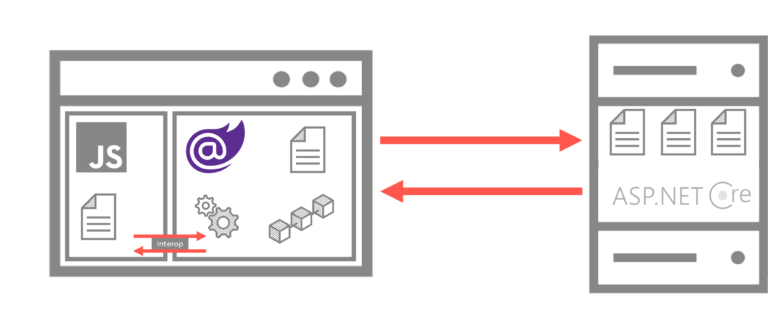
Mittels der PWA-Erweiterungen (Progressive Web Apps) für Blazor WebAssembly ist es, wie auch bei reinen JavaScript-basierten SPAs, möglich, die Anwendung durch das Bereitstellen eines sogenannten Manifestes und eines Service Workers im Browser zwischenzuspeichern und damit eine vollständig offline fähige Anwendung zu erstellen. Natürlich stehen uns in der JavaScript-Runtime des Browsers auch nur Browser-APIs zur Verfügung. Von hier aus können z.B. keine normalen Socket-Verbindungen aufgebaut werden, wie es z.B. für einen Datenbankzugriff notwendig ist.
Blazor Server
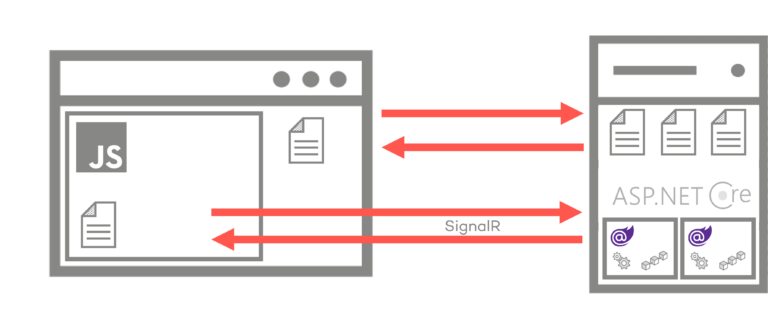
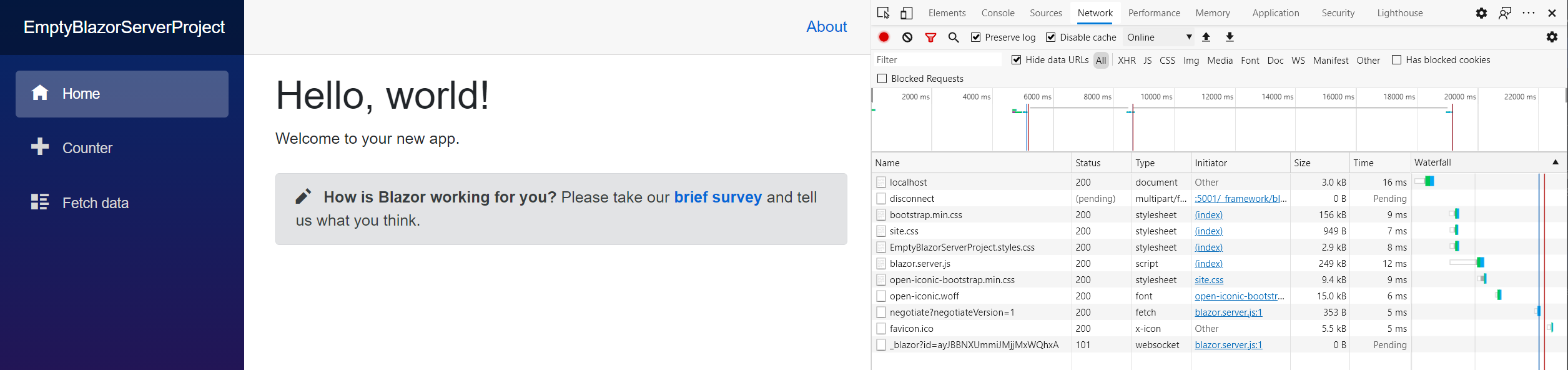
Wie man auf dem folgenden Screenshot sieht, wird auch hier wieder ein JavaScript geladen, aber dann wird die SignalR-Verbindung aufgebaut und die Anwendung läuft.
Und ja: Die Ähnlichkeit dieses Konzeptes mit Mainframes (Server) und Terminals bzw. Thin-Clients als Eingabe-Ausgabe-Schnittstelle (Browser) sind nicht von der Hand zu weisen.
Was bedeutet dieser Unterschied?
- Es wird eine permanente Verbindung zwischen Server und Browser benötigt. Blazor Server Anwendungen sind grundsätzlich nicht offline-fähig.
- Wir unterliegen keinen API-Limits des Browser mehr: Zugriffe unseres Codes auf dem Server auf spezielle Schnittstellen und externe Hardware fallen deutlich leichter (z.B. Industriemaschinen, Scanner, Sensoren, Bus-Systeme, direkte Datenbankzugriffe etc.). Auch, weil nun sehr leicht externe Bibliotheken dafür eingebunden werden können.
- Auf dem Server kann unsere Anwendung mit anderen APIs über beliebige Protokolle kommunizieren. Eine aufwendige Anpassung an das Web oder Serialisierung/Deserialisierung über HTTP(S) können entfallen.
Da die Anwendung auf dem Server ausgeführt wird, und nur die reine HTML-Oberfläche ohne Logik im Browser, benötigen wir jedoch eine permanente, stabile Netzwerk-Verbindung zwischen unserem Browser und dem Webserver. Idealerweise haben wir hier auch eine möglichst niedrige Latenz, damit unsere Eingaben möglichst schnell zum Server kommen, bearbeitet werden und die Antwort wieder zurückkommt. Haben wir eine große Latenz, fühlt sich die Anwendung extrem langsam an und der Nutzer muss für jede einzelne Aktion an der Oberfläche lange warten bis die Anwendung reagiert. Der Benutzer sollte also im besten Fall möglichst nahe am Server verortet und möglichst latenzfrei (LAN statt WAN) angebunden sein.
Der Ansatz, die Anwendung auf dem Server laufen zu lassen, bedeutet auch, dass der Server für alle gleichzeitigen Nutzer die entsprechenden Ressourcen bereithalten muss. Das sind zum einen Netzwerkanbindung und -bandbreite, zum anderen aber vor allem ausreichend Arbeitsspeicher, um den Zustand aller gleichzeitigen Verbindungen zu halten und zum dritten ausreichend CPU-Kapazitäten, falls die Anwendung rechenintensive Aufgaben für jeden Nutzer ausführen muss. Im Gegenzug wird hier der Client entlastet und so kann unsere Webanwendung auch auf eher schwachen Rechnern wie z.B. Chromebooks oder Tablets wie z.B. den günstigen Amazon Fire-Geräten effizient genutzt werden.
Der zweite Punkt eröffnet uns dabei sehr interessante Möglichkeiten: Wir können beispielsweise direkt aus unserer Webanwendung heraus auf Datenbanken zugreifen, ohne erst eine Web-API zwischen dem Web-Frontend und dem Server-Backend entwerfen und implementieren zu müssen. Dies erspart viel Arbeit. Genauso können wir z.B. schon existierende Bibliotheken weiterverwenden, auch wenn wir diese nicht nach WebAssembly kompilieren können.
Wann nehme ich was?

Blazor WebAssembly ist geeignet, wenn unsere Anwendung auch offline funktionieren soll. Auch wenn wir starke Clients haben, können wir die Last dorthin verschieben und von den Browser-APIs profitieren. Dies ermöglicht uns, die Anwendung als echte Progressive Web-App zu erstellen. Wir müssen jedoch bedenken, dass vor allem Firewalls von Firmen hier etwas übereifrig sein und unsere Anwendung blockieren könnten.
Blazor Server ist dann eine Option, wenn man sicherstellen kann, dass alle Clients eine stabile Netzwerkverbindung mit geringer Latenz zum Server haben. Wenn unsere Anwendung ressourcenintensiv ist, kann diese so auch für günstige Client-Geräte nutzbar gemacht werden, indem wir zentral auf dem Server die entsprechenden Ressourcen bereitstellen. Wenn unsere Anwendung vom Server aus unmittelbar mit speziellem Code, APIs oder Bibliotheken kommunizieren muss, und diese nicht als Web-APIs bereitstehen bzw. nur sehr aufwändig bereitzustellen sind, kann Blazor Server auch den Aufwand eine Oberfläche zu Web-ifizieren reduzieren. In solchen Fällen bietet Blazor Server die Möglichkeit, diesen Code mit weniger Aufwand in einer neuen, Web-basierten Anwendung wiederzuverwenden. Allerdings ist dies genau so bei ASP.NET MVC oder Razor-Pages Anwendungen der Fall.
Auch die dritte Option, beides zu kombinieren, möchte ich an dieser Stelle nicht verschweigen: Man kann z.B. eine Anwendung primär als Blazor WebAssembly bereitstellen, aber für die Benutzer, die z.B. durch eine Firewall am Download der Assemblies gehindert werden, die gleiche Anwendung als Fallback auch in der Server-Version betreiben.
Zuletzt rufen wir uns wieder ins Gedächtnis, dass Blazor in beiden Fällen einfach Blazor ist. Wir können also eine (UI-)Komponentenbibliothek und auch die Businesslogik so erstellen, dass sie unabhängig von den jeweils speziellen APIs ist. Diesen Code können wir dann in Anwendungen verwenden, die wir mit Blazor WebAssembly auf die Geräte schieben – und zeitgleich auch in anderen Blazor Server-Anwendungen wiederverwenden.
Blazor @ Thinktecture
Oftmals werden wir gefragt, welche Technologie aus unserer Sicht “die richtige” sei. Das hängt selbstverständlich immer von allen Gesamtumständen ab und es gibt darauf keine universelle Antwort. Dennoch haben wir eine Meinung dazu:
Grundsätzlich – komplett unabhängig von Technologieen – stellt sich bei Web-basierten Anwendungen heutzutage immer auch noch die Frage, ob es eine SPA sein muss, oder ob eine klassische, vom Server gerenderte, Webanwendung nicht doch ausreicht. SPAs kommen dabei zwangsläufig immer mit einer etwas höheren Komplexität daher: Wir bauen eine Fat-Client Anwendung mit eigener Zustandshaltung und diesen müssen wir irgendwie mit dem Zustand auf dem Server synchron halten. Wir müssen die Browser-Navigation mit einbeziehen (Routing), wir sind auf Browser-APIs beschränkt. Diese höhere Komplexität bietet uns aber bei Progressive Web Apps (PWA) eben auch die Möglichkeit, eine vollständig offlinefähige und damit “richtige” Mobile-App zu bauen – und dabei alles aus der Plattform Web herauszuholen was sie uns anbietet, ohne plattformspezifischen Code schreiben zu müssen. Generell sagen wir daher: Eine SPA ergibt genau dann Sinn, wenn wir sie auch wirklich benötigen. Brauchen wir die Optionen die uns eine SPA bietet nicht, spricht eher vieles für klassische Server-Rendered Anwendungen, denn es ist in der Tat viel einfacher.
Und was bedeutet das für Blazor?

Blazor Server ist, wie der Name schon sagt, eine Server-Technologie. Wenn unsere Webanwendung also sowieso schon auf dem Server leben muss und offline gar nicht funktionieren kann, dann stellen wir uns natürlich die Frage, warum man die Anwendung dann nicht gleich als eine normale Server-Rendered Anwendung, z.B. mit ASP.NET Core MVC oder Razor Pages erstellt? Welchen Mehrwert würde uns Blazor Server bieten, um den Mehraufwand und die höhere Komplexität einer SPA-Technologie zu rechtfertigen? Wir finden: Eigentlich keinen.
Blazor WebAssembly ist hingegen ein richtiges SPA-Framework das es uns ermöglicht echte Browser-basierte Anwendungen zu bauen die auch in der Lage sind, alle SPA-Vorteile voll auszuspielen.
Fazit
Blazor WebAssembly wird im Web-Browser ausgeführt, wohingegen eine Blazor Server-Anwendung auf dem Server “lebt”. Blazor Server ist mit seinem Ansatz eher mit einer Anwendung die via “Remote Desktop” bzw. “X11 fürs Web” bereitgestellt wird zu vergleichen. Der Ansatz von Blazor WebAssembly erlaubt es, eine richtige, potentiell auch rein offlinefähige, Single-Page Application zu erstellen. Blazor-Komponenten können, sofern sie der richtigen entkoppelten Architektur folgen, ohne Änderungen in beiden Anwendungsmodellen verwendet werden.
Bei der Entscheidung, welche dieser Technologien die richtige für ein Projekt ist, muss man unter anderem die Punkte der gegebenen Netzwerkumgebung, das Lastverhalten und die Verfügbarkeit bzw. die Abhängigkeiten von Browser- bzw. Serverspezifischen APIs berücksichtigen.

Blazor Server kann dabei ein Sprungbrett hin zur echten SPA sein oder ein Fallback falls es technische Schwierigkeiten mit dem Deployment-Modell von WebAssembly gibt. Falls man allerdings keine SPA benötigt, sind Server-Rendered Anwendungungen wie Razor Pages oder ASP.NET Core MVC genau so gute Alternativen zu Blazor Server.