Was genau bedeutet "offline" eigentlich?
Ob Chrome’s „Dino“, „Sorry :-(“ oder „Keine Verbindung zum Server möglich“ – alle drei (und noch mehr) sind uns bekannte Informationen, dass wir eine Anwendung aktuell nicht benutzen können. In der Regel passiert das selten im eigenen Zuhause, wo wir mit Kabel oder (hoffentlich) gutem Wi-Fi verbunden sind. Sobald wir allerdings mit dem Zug oder im Auto unterwegs sind oder fremde Länder bereisen, werden wir diese Meldungen durchaus öfter sehen. Die WLAN-Verbindung bricht ab, kein Zugang zu LTE oder zu hohe Roamingkosten im Ausland können Faktoren sein, warum unsere App sich nicht mit ihrem Server verbinden kann oder darf.

Doch zuerst muss man sich die Frage stellen, was bedeutet offline eigentlich genau?
Auch wenn ein Smartphone eine Edge- oder sogar eine LTE-Verbindung anzeigt, muss das nicht zwingend bedeuten, dass man tatsächlich online ist. Ein Server kann dennoch nicht (verlässlich) erreichbar sein.
Wir müssen, um zu erkennen ob wir wirklich online sind, nicht nur prüfen ob generell eine Verbindung zum Internet besteht, sondern auch ob die Verbindungsqualität und -geschwindigkeit ausreichend ist. Im Falle einer App müssen wir auch prüfen, ob unsere Services erreichbar sind. Hier ist es abhängig vom Use-Case, was dann genau „online“ bedeutet:
- Müssen die Server innerhalb einer kurzen Zeit antworten?
- Muss eine gewisse Bandbreite erreicht werden bzw. zur Verfügung stehen?
- Müssen zusätzlich zur API auch die dahinter genutzten System ansprechbar sein?
Eine offlinefähige Angular-Anwendung
Generell kann man beim Entwickeln von offlinefähigen Anwendungen zwei Arten unterscheiden. Es gibt offline gecachte Daten und offline synchronisierte Daten.
Im Falle von offline gecachten Daten können wir uns die Anwendung wie einen Web Browser vorstellen. Man surft durch seine Anwendung und diese speichert alle Daten, die wir uns bisher angesehen haben, in einem Offline-Cache. Fällt die Verbindung zum Server aus, können wir zwar die bereits aufgerufenen Daten weiterhin anschauen, aber keine nicht-gecachten Daten, da für diese weiterhin der Server benötigt wird. Dazu kommt, dass sich diese Art des „Cachings“ nur für den reinen lesenden Zugriff eignet. Zum Anlegen eines neuen Datensatzes benötigen wir dann in der Regel zwingend eine Verbindung zum Server.
Die zweite Art offline synchonisierte Daten bedeutet, dass die Anwendung nach dem Start, dann auch meist in Kombination mit einem Login, im Hintergrund alle ihr zur Verfügung stehenden, beziehungsweise benötigten Daten, automatisch herunterlädt – und das auch, wenn der Benutzer diese Daten noch gar nicht angefordert hat. Das Prinzip kennen wir beispielsweise von Microsoft OneNote. Dort können wir ein Notizbuch öffnen und auch wenn wir uns noch gar nicht für alle Notizen interessieren, werden diese automatisch im Hintergrund, Notiz für Notiz, heruntergeladen. Ist dann das Endgerät offline, können dennoch alle bereits synchronisierten Daten angesehen werden, auch wenn wir diese, als OneNote noch einen Online-Zugriff hatte, gar nicht aufgerufen haben. Bei dieser Art ist es auch oft möglich, dass neue Daten angelegt werden können, auch wenn die Anwendung zu diesem Zeitpunkt offline ist. Sobald erneut Verbindung zum Server besteht, können die Daten in beide Richtungen synchronisiert werden. Hierbei kann es durchaus zu Konflikten kommen, aber dazu später mehr.
Eine Angular-Anwendung "einfach" offline nehmen
Nachdem wir geklärt haben, was offline bedeutet und welche Arten von offlinefähigen Anwendungen existieren, stellt sich die nächste Frage: Wie bekomme ich meine eigene Anwendung offline?
Oft stellt man sich diese Frage erst später, nach dem die Anwendung bereits mit einer notwendigen, permanenten Serververbindung fertiggestellt im Einsatz ist. Aus diesem Grund wollen wir uns im Artikel auch mit einer Brownfield-Anwendung und nicht mit einer Greenfield-Anwendung beschäftigen. Wir migrieren eine reine Online-App zur Offline-App.
Die Brownfield-Applikation – „Thinktecture Boardist“
Als Basis werden wir die Anwendung „Thinktecture Boardist“ nutzen, eine SPA zur Verwaltung von Brettspielen, deren Publishern, den Spielmechaniken, Regelwerken in Form von PDFs und natürlich den Autoren und Illustratoren. Der develop-Branch beinhaltet eine vollständige, rein onlinefähige Anwendung mit Backend und wird als Basis für diesen Artikel verwendet. Gemeinsam wollen wir aus dieser Anwendung eine offlinefähige Version entwickeln inklusive offline-synchronisierten Daten.
Das Backend ist mit .NET Core MVC in C# entwickelt und greift via Entity Framework Core auf eine in Azure betriebene Microsoft SQL-Datenbank zu. Das Frontend wurde mit Angular umgesetzt. Die folgenden Codebeispiele sind daher in C# und TypeScript. Die Konzepte und Ideen, um aus einer Brownfield-Anwendung eine offlinefähige Anwendung weiterzuentwickeln, können jedoch auch mit anderen Sprachen, Frameworks und Datenbanksystemen adaptiert werden.
Das Datenmodell
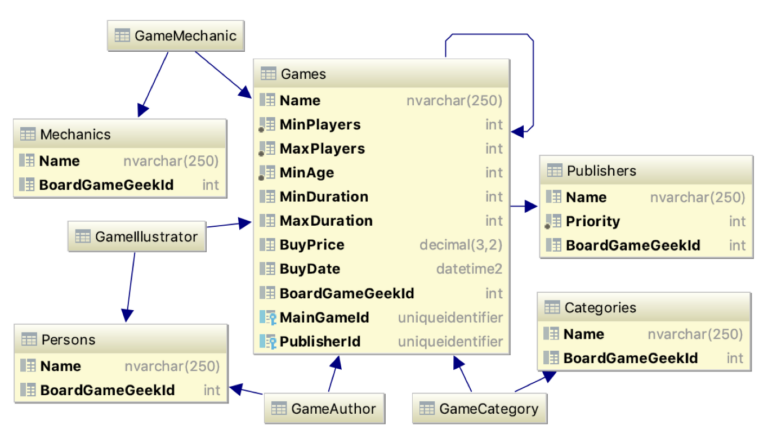
Hier sehen wir das Datenmodell von Boardist. Es ist ein klassisches relationales Modell mit entsprechenden Beziehungen. Es ist durch Code-First von Entity Framework Core angelegt worden. Generell findet sich in jeder Entitätstabelle die Referenz zum Eintrag bei BoardGameGeek™ – die Webseite zum Thema Brettspiele. Von dort kann der Server die meisten Daten automatisch importieren.
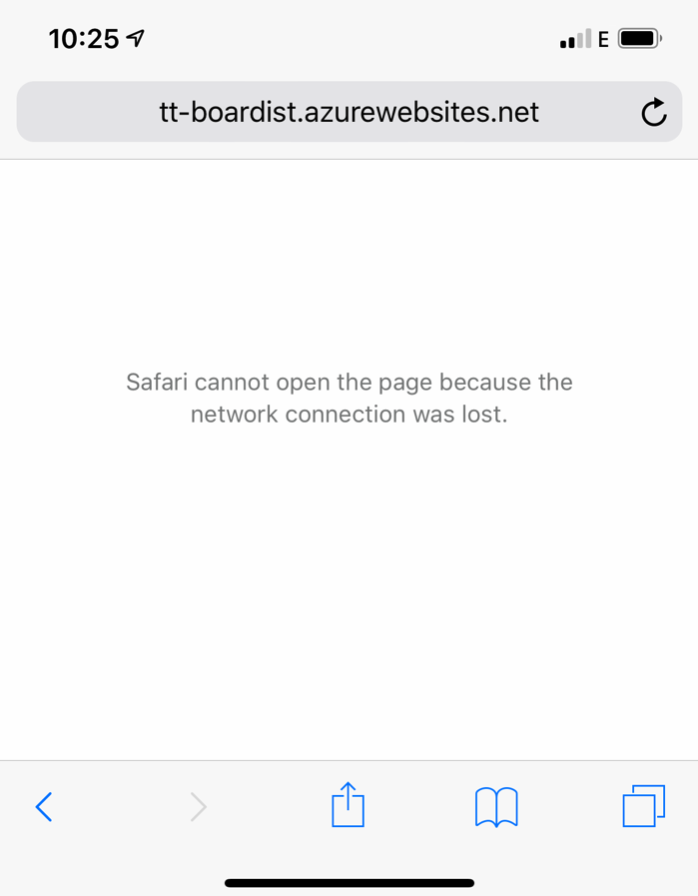
Der erste Versuch – eine PWA
Um mit Angular aus einer SPA eine PWA zu erstellen ist nur ein Schritt notwendig. Ein Service Worker zusammen mit den notwendigen Anpassungen werden einfach über ein Kommando mit der Angular CLI installiert:
ng add @angular/pwa
Um die Anwendung zu testen, müssen wir diese leider vollständig als Production Build bauen – mit dem serve Kommando wird der Service Worker nicht aktiviert:
ng build --prod
Wenn wir uns den Network-Tab in den Chrome Dev Tools anschauen, werden wir feststellen, dass alle Anfragen mit einem kleinen Zahnrad versehen sind:
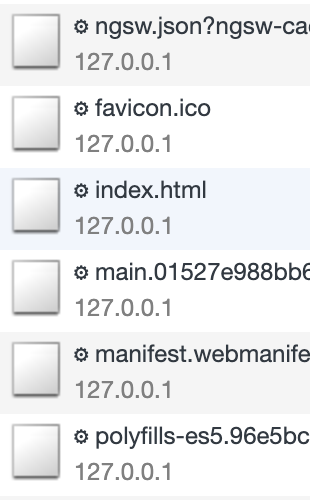
Dies bedeutet, dass alle Anfragen durch den Service Worker beantwortet werden. Dieser schaut zuerst in seinem lokalen Cache nach, ob die angefragte Ressource verfügbar ist. Falls nicht ruft er diese beim Ursprung ab. In der Standardkonfiguration, erstellt durch die CLI, werden aber nur Angular-bekannte Elemente in den Cache gelegt. Bei unserer App werden noch weitere Elemente von zum Beispiel dem Google CDN geladen. Wenn wir den Browser auf Offline schalten, stellen wir fest, dass genau diese Ressourcen nicht gecacht und somit offline nicht verfügbar sind:
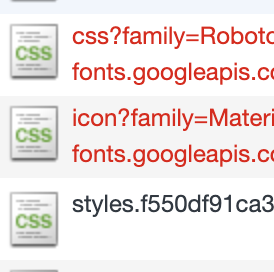
Da eine API auch äußerst dynamisch hinsichtlich der URL sein kann, wäre ein Aufzählen aller möglichen Kombination eher ein weniger praktikables Vorgehen, um eine Anwendung offline verfügbar zu machen. Für unseren Fall ist eine PWA somit leider noch nicht ausreichend, sie sorgt nur dafür, dass unsere Anwendung aus Code-Seite im Browser offline verfügbar ist. Für die Daten brauchen wir eine echte Offlinefähigkeit.
Für mehr Informationen zum Thema PWA Offlineanwendungen empfiehlt sich das Webinar PWA Deep Dive: Offlineanwendungen im Griff unseren Kollegen Christian Liebel.
Selbst ein Definieren aller URLs mit Platzhaltern (sog. Wildcards) im dynamischen Bereich der Service-Worker-Konfiguration ist nicht zielführend, da der Abruf weiterhin nicht automatisch erfolgt, sondern erst, wenn der Benutzer dies anfordert. Und ein stupider „Automatismus“ würde zu viele unnötigen Abfragen erzeugen, da damit nicht differenziert werden kann, ob die Daten bereits auf dem Client vorhanden sind – es fehlt eine Differenzprüfung.
Eine Angular Anwendung "wirklich" offline nehmen
Eine Anwendung mit Offlinedaten sorgt dafür, dass alle notwendigen Daten im Browser verfügbar sind, auch wenn keine Netzverbindung besteht. Sie hält diese Daten auch immer aktuell, sprich, sie entfernt veraltete Daten und lädt selbständig neue Daten herunter. Dies kann periodisch erfolgen (z.B. alle 5 Minuten) oder durch ein Signal vom Server (z.B. über eine WebSocket-Verbindung).
Offline Speicher
Um Daten offline zu halten, bieten sich im Browser einige Speichermöglichkeiten an:
Web Storage
Bei einem Web Storage handelt sich um den Session, beziehungsweise Local Storage. Der Unterschied zwischen den beiden ist nur, dass der Session Storage nach dem Schließen des Tabs/Browsers automatisch gelöscht und nicht zwischen mehreren Tabs geteilt wird. Beide sind auf jeweils maximal 5MB Gesamtgröße beschränkt. Dies ist nicht viel und für die meisten Anwendungen eher nicht ausreichend. Somit fällt dieser Speicherort leider raus.
Cache Storage
Der Name klingt verlockend, aber es ist trotzdem nicht der richtige Ort für unsere Offlinedaten. Der Nachteil beim Cache Storage ist, dass dieser Request/Response-basiert genutzt wird und eigentlich dafür gedacht ist, die durch einen Service Worker geleiteten Anfragen komfortabel darin abzulegen. Folglich ist dies kein Kandidat für unsere Daten, denn eine Abfrage nach den „neuesten“ Daten sieht aus Abfragesicht immer gleich aus. Allerdings liefert er unterschiedliche Ergebnisse und stellt erstmal nur (vereinfacht) ein leeres Array dar, bis es neue Daten gibt
IndexedDb
Bei der IndexedDb handelt es sich um einen sogenannten Key/Value-Store, unterteilt in einzelne Datenbanken mit darin enthaltenen Tabellen. Dieser Aufbau ist prädestiniert zum Ablegen von Offlinedaten. Verfügbar ist die IndexedDb in jedem modernen Browser. Leider basiert die API noch auf Callbacks und wäre eher umständlich zu nutzen. Aber wie so häufig gibt es bereits eine komfortable Open Source Library, Dexie.js, welche das Ganze per Promise viel einfacher und moderner nutzen lässt. Hinsichtlich der maximalen Größe dieses Bereichs gibt es unterschiedliche Angaben. Je nach Browser-Hersteller und Plattform kann es bis zu der Hälfte des freien Speicherplatzes oder eine harte Obergrenze von 500 MB sein. Generell sollten keine Binärdaten abgelegt werden, da dies unter Umständen zu Performance-Problemen führen kann. Zusätzlich belegen Dateien im Regelfall mehr Platz als einfache Daten und sollten somit besser im Dateisystem gespeichert werden.
Konzept einer Offline-Synchronisation
Bei einer Offline Synchronisation werden alle notwendigen Daten, die für den Client während er offline ist trotzdem zur Verfügung stehen sollen, in einen persistenten Speicher geladen. Die sollte im Regelfall ohne eine Notwendigkeit des Benutzers erfolgen, d.h. die Anwendung macht dies selbständig im Hintergrund. Es gibt aber durchaus Szenarien, in denen der Benutzer explizit entscheidet, was er gerne offline vorhalten möchte. Ein konkretes Beispiel wäre zum Beispiel die App von Dropbox. Dort kann entschieden werden, welche Dateien und/oder Verzeichnisse für den Offlinezugriff gespeichert werden sollen.
Folgende Anforderungen sind an den Code im Frontend für die Offline-Synchronisation zu stellen:
- Neue Daten hinzufügen
- Veränderte Daten ersetzen
- Veraltete Daten löschen
- Prüfen, ob ein Online-Zugriff möglich ist oder die Anwendung gerade offline ist
- Bei Bedarf auf Konflikte eingehen, falls ein Ändern von Offlinedaten durchgeführt werden kann
- Fehlertolerant sein, das heißt nicht abstürzen, wenn während der Synchronisation etwas schiefläuft
- Von Grund auf eine vollständige Synchronisation durchführen können, um bei Bedarf inkonsistente Daten zu korrigieren
Auf Seiten des Backends gibt es folgende Anforderungen:
- Geänderte Daten müssen erkannt werden
- Neue Daten müssen erkannt werden
- Gelöschte Daten müssen erkannt werden
- Konflikte müssen erkannt werden
Bleiben wir erstmal auf der Backend-Seite und betrachten die oben genannten Punkte genauer. Generell ist es hier am besten, wenn die Datenbank eine Unterstützung hierfür bietet. In unserem Fall setzen wir Microsoft SQL Server) ein. Mit diesem steht uns ein Spaltentyp zur Verfügung, der genau die Anforderungen erfüllt, die wir brauchen. Es handelt sich hierbei um den Typ rowversion. Der Wert in der Spalte zählt sich immer automatisch hoch, wenn die Zeile eine Änderung erfährt (und zwar zum Zeitpunkt der Änderung, nicht zum Zeitpunkt des Abschlusses der Transaktion). Die Befürchtung dieser Wert, da er ja Datenbank-Global hochgezählt wird, könnte überlaufen ist nicht berechtigt. Er entspricht einem 64-bit Binärarray welches mit dem Wert 0x0000000000000001 beginnt und dann bitweise hoch zählt. Der größte Wert entspricht, da es vorzeichenlos ist, also keine Negativwerte beinhaltet, 0xffffffffffffffff (als Dezimalzahl 18.446.744.073.709.551.615, oder in Worten Achtzehn Trillionen Vierhundertsechsundvierzig Billiarden Siebenhundertvierundvierzig Billionen Dreiundsiebzig
Milliarden Siebenhundertneun Millionen Fünfhunderteinundfünfzig Tausend Sechshundertfünfzehn) Datenänderungen. Würde man nun theoretisch jede Sekunde 500.000 Änderungen durchführen, reicht der Wertebereich für knapp Siebenunddreißig Billionen Sekunden. Dies sind vereinfacht 1,1 Millionen Jahre – mehr als ausreichend. Durch diese Information können wir geänderte und neue Datensätze in einer Tabelle erkennen. Nur beim Löschen hilft uns diese Spalte im ersten Moment vermeintlich nicht weiter, da der betroffene Datensatz nicht mehr vorhanden ist. Wir haben aber zwei Möglichkeiten, damit umzugehen. Entweder wir markieren die Daten nur als gelöscht oder wir speichern beispielsweise per Datenbank-Trigger den beziehungsweise die gelöschten Primärschlüssel, um dem Frontend eine Liste von gelöschten Werten übergeben zu können. Das Frontend nutzt diese Schlüssel, um dann etwaige vorhandene Daten im Offline-Speicher zu löschen. Zum Reduzieren der Datenmenge können wir auch wieder die rowversion einsetzen, um nur die neuesten Werte bei der Synchronisation zu beachten. In diesem Beispiel entscheiden wir uns für die Markierung von zu löschenden Daten mit einer IsDeleted Spalte.
Anpassungen in der Datenbank
Dies bedeutet, dass der erste Migrationsschritt das Hinzufügen einer rowversion wie auch der IsDeleted Spalte in jeder Tabelle sein wird, die später im Frontend offline verfügbar sein soll. Dies könnte mit dem folgenden SQL-Kommando pro Tabelle erreicht werden:
ALTER TABLE [tabelle] ADD RowVersion rowversion, IsDeleted bit default 0 not null;
Anpassungen im Code-First-Modell
Da wir in unserem Projekt Entity Framework Core einsetzen, können wir dies direkt in unseren Entitäten durchführen und dann die Datenbank durch eine Migration anpassen lassen. Ein Beispiel zeigt die Änderung an der Entität Person:
public class Person
{
/* … */
public ulong RowVersion { get; set; } // <--
public bool IsDeleted { get; set; } // <--
}
Der C# Typ ulong ist noch nicht ausreichend, um Entity Framework Core dazu zu bewegen, eine rowversion Spalte zu erstellen. Dazu muss die Property noch in der Entitätskonfiguration detaillierter festgelegt werden:
public class PersonEntityTypeConfiguration : IEntityTypeConfiguration<Person>
{
public void Configure(EntityTypeBuilder<Person> builder)
{
/* … */
builder.Property(p => p.RowVersion)
.HasColumnType("rowversion")
.IsRowVersion(); // <--
}
}
Was genau passiert hier? Da der Typ der Property ulong ist, reicht ein einfaches IsRowVersion() nicht aus. Zuerst muss der Spaltentyp in der Datenbank festgelegt werden, denn mit dem definierten Typ würde die Spalte nicht funktionieren. Da der Spaltentyp in der Datenbank als Byte-Array verwaltet wird, käme es zu einem Fehler, wenn die Daten so gelesen werden würden. Aus diesem Grund benötigen wir hier noch einen Konverter, der aus dem ulong ein Byte-Array (und umgekehrt) macht. Zusätzlich muss die Endianess beachtet werden, da die Datenbank die Zahl als Big-Endian speichert, aber C# Zahlen in Little-Endian erwartet:
public class PersonEntityTypeConfiguration : IEntityTypeConfiguration<Person>
{
public void Configure(EntityTypeBuilder<Person> builder)
{
/* … */
var converter = new ValueConverter<ulong, byte[]>( // <--
l => BitConverter.GetBytes(l).Reverse().ToArray(), // <--
b => BitConverter.ToUInt64(b.Reverse().ToArray()) // <--
); // <--
builder.Property(p => p.RowVersion)
.HasColumnType("rowversion")
.IsRowVersion()
.HasConversion(converter); // <--
}
}
Wenn wir das bei jeder Entität durchgeführt haben, können wir eine Migration erstellen, um die Datenbank anzupassen:
dotnet ef migrations add Add_Offline_Columns
Wir können nach dem nächsten Starten der API in der Datenbank sehen, dass die Spalten angelegt wurden (die API migriert die Datenbank beim Start automatisch):
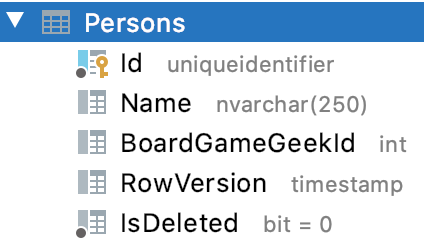
Dass hier timestamp steht, ist dem Tool JetBrains DataGrip geschuldet. Es zeigt rowversion-Spalten mit dem Alias an. Beide Typen können an dieser Stelle gleichbedeutend verwendet werden. Mit dieser neuen Spalte können wir erkennen, ob ein Datensatz geändert wurde oder sogar neu dazugekommen ist. Dazu ist es nur notwendig, dass dem Backend beim Abfragen einer Entität mitgeteilt wird, was der zuletzt bekannte Wert einer rowversion-Spalte ist. Damit können dann durch eine einfache WHERE-Bedingung die entsprechenden Datensätze ermittelt werden. Im Falle von LINQ sieht dies folgendermaßen aus:
context.Persons.Where(p => p.RowVersion >= rowVersion);
Wenn wir uns bei der RowVersion-Property anstatt für ulong für das tatsächliche byte[] entschieden hätten, würde hier kein einfacher Größer-Gleich-Vergleich funktionieren, da man Byte-Arrays in C# nicht direkt miteinander vergleichen kann.
API-Endpunkt für die Synchronisation
Mit dieser Vorbereitung können wir einen API-Endpunkt bauen, der uns die geänderten (und neuen) Personen sowie die gelöschten zurückgibt. Diese verpacken wir in ein passendes DTO:
public class PersonSyncDto
{
public byte[] Timestamp { get; set; }
public ICollection<PersonDto> Changed { get; set; }
public ICollection<Guid> Deleted { get; set; }
}
Das DTO beinhaltet eine Liste aller PersonDto, die geändert oder neu sind, sowie die GUIDs der gelöschten (in unserem Fall in der Datenbank nur gelöscht markierten) Personen. Zusätzlich übergeben wir dem Frontend einen passenden Timestamp, den es bei der nächsten Abfrage wieder ans Backend zurück übermittelt. Daran stellt das Backend fest, ob sich seit dem letzten Abruf weitere Daten geändert haben. Bei der Ermittlung dieses Wertes gibt es verschiedene Möglichkeiten an diesen zu kommen, aber nur eine davon ist am Ende valide. Schauen wir uns diese mal an:
Möglichkeit 1: Größter (neuester) Wert im Ergebnis bzw. der Tabelle
Die Nutzung der größten rowversion in der Tabelle bzw. vom Ergebnis führt zum Verlust von Änderungen. Warum? Schauen wir uns ein Beispiel mal an:
Sobald mehr als eine Transaktion aktiv ist und eine später erstellte davon zuerst abgeschlossen wird, ist der höchste Wert in der Tabelle höher als die Werte in den noch aktiven Transaktionen. Bis diese Transaktionen abgeschlossen werden, würde das Frontend aber bereits den höheren Wert abgelegen und dann bei der nächsten Prüfung diese Änderungen nicht mehr „sehen“, da sie durch den Größer-Gleich-Vergleich herausgefiltert werden:
Zustand | Library | RowVersion | |
#1 | Offen | 1001 | |
#2 | Abgeschlossen | 1002 | |
#3 | Offen | 1003 |
Da im Beispiel die Transaktion #2 abgeschlossen ist, würde eine Abfrage auf die höchste rowversion den Wert 1002 ergeben. Wenn eine neue Prüfung unabhängig vom Abschließen der Transaktion #1 mit diesem Wert erfolgt, wird die Änderung aus der später abgeschlossenen (aber früher begonnenen) Transaktion nicht mehr berücksichtigt, da deren rowversion bereits mit dem Ändern der Daten gesetzt wurde.
Möglichkeit 2: Abfrage des Systemwertes @@DBTS
Der Systemwert @@DBTS reflektiert die zuletzt vergebene rowversion in der Datenbank – unabhängig, ob eine Transaktion noch offen ist oder bereits abgeschlossen wurde. Aus diesem Grund kann dieser Wert ebenfalls nicht verwendet werden, da er noch viel früher ein zu hohes Ergebnis liefert:
Zustand | Library | RowVersion | |
#1 | Offen | 1001 | |
#2 | Abgeschlossen | 1002 | |
#3 | Offen | 1003 |
Im Beispiel betrachten wir drei Transaktionen, von denen die Transaktion #2 bereits abgeschlossen wurde. Da aber in Transaktion #3 die rowversion auf 1003 gesetzt wurde, erhalten wir diesen Wert, wenn wir @@DBTS abfragen. Somit würde die später abgeschlossene Transaktion #1 erneut nicht berücksichtigt werden.
Möglichkeit 3: Nutzung der Funktion MIN_ACTIVE_ROWVERSION()
Diese Funktion liefert das korrekte Ergebnis, denn sie gibt den kleinsten, sich noch in einer Transaktion befindenden Wert zurück. Aus diesem Grund werden keine Änderungen übersprungen. Manchmal kann es dazu führen, dass solange Transaktionen noch laufen, die gleichen Daten erneut in das Abfrageergebnis gelangen. Dies könnte aber erst zu einem Problem werden, wenn es zu sehr langen Transaktionslaufzeiten kommt oder die wiederholten Daten enorm groß werden:
Zustand | Library | RowVersion | |
#1 | Offen | 1001 | |
#2 | Abgeschlossen | 1002 | |
#3 | Offen | 1003 |
Da die Transaktion #1 noch nicht abgeschlossen ist, liefert MIN_ACTIVE_ROWVERSION() 1001 unabhängig von den nachfolgenden Transaktionen und deren Zustand. Dadurch wird aber auch der Datensatz aus Transaktion #2 die ganze Zeit als geändert geliefert (und gegebenenfalls später auch der aus Transaktion #3).
Wichtig hier ist, den Wert, der an den Client im Ergebnis übermittelt wird, vor dem Abfragen der eigentlichen Daten schon zu ermitteln.
Der finale Code zum Abfragen der Daten sieht dann folgendermaßen aus:
var rowVersion = Convert.FromBase64String(frontendTimestamp ?? EmptyRowVersion).ToBigEndianUInt64();
var timestamp = await _boardistContext.GetMinActiveRowVersionAsync(); // <-- der "zukünftige" Timestamp
var baseQuery = _boardistContext.Persons.Where(p => p.RowVersion >= rowVersion);
var changed = await baseQuery.Where(p => !p.IsDeleted).Select(p => /* … */).ToListAsync();
var deleted = await baseQuery.Where(p => p.IsDeleted).Select(p => p.Id).ToListAsync();
return new PersonSyncDto { Timestamp = timestamp.ToBigEndianBytes(), Changed = changed, Deleted = deleted };
Das Frontend übermittelt eine optionale rowversion als Base64-encodierter String, da diese als Byte-Array später übermittelt wird (die Serialisierung nach JSON erstellt davon automatisch ein Base64-String). Die EmptyRowVersion ist effektiv die Zahl 0 und sorgt dafür, dass jede rowversion selektiert wird, wenn kein Wert übergeben wurde.
Alle diese Anpassungen reichen aus, um das Backend „offlinefähig“ zu machen. Da noch weitere Entitäten für das Frontend als Offlinedaten zur Verfügung stehen sollen, kann dieser Code recht einfach in einen generischen Ansatz umgestaltet werden und ist so auch bereits im Repository im Branch offline zu finden.
Erweiterung des Frontends
Das Frontend im online-only Zustand lädt die jeweiligen Daten mit auf Promise-basierende HTTP-Abfragen. Wir brauchen einen passenden Ort zum Speichern der Daten, die im gleich erstellten Synchronisationsprozess abgefragt werden. Statt der HTTP-Abfrage fragen wir die Daten dann einfach von der IndexedDb mit Dexie.js ab. Ein recht einfach erklärter Vorgang, der in Code gegossen werden kann.
Anlegen der IndexedDb mit Dexie.js
Das Definieren von Datenbanken und den darin enthaltenen Tabellen mit entsprechenden Indizes, ist mit Dexie.js sehr einfach gelöst. Dazu muss man nur von der Klasse Dexie ableiten und im Konstruktor den obligatorischen super-Aufruf mit dem gewünschten Datenbank-Namen machen. Danach kann man auf der Methode version beginnend mit der Version 1 die Tabellen (sog. Stores) definieren (für’s erste wieder nur das Person Beispiel):
this.version(1).stores({
timestamps: 'name',
/* … */
persons: 'id',
});
Falls es später, nachdem die Stores bereits erstellt wurden, zu Änderungen in der Definition kommt, kann dies durch das aufzählen einer weiteren Version erfolgen. Hierbei muss aber dann mit anzupassenden Daten per manueller Migration umgegangen werden (weitere Infos dazu in der Dokumentation von Dexie.js). Zusätzlich haben wir auch schon die Tabelle timestamps definiert. Diese brauchen wir in unserem Code zur Synchronisation der Daten, dazu dann gleich mehr.
Synchronisieren der Daten
Nachdem wir die Möglichkeit zum Speichern der Daten entwickelt haben, können wir uns jetzt dem eigentlichen Synchronisationscode widmen. Die generelle Vorgehensweise wäre zum Beispiel periodisch den entsprechenden Synchronisationsendpunkt aufzurufen. Dies könnte man ganz klassisch mit einem direkten setInterval-Aufruf bewerkstelligen oder, wenn man in Streams denkt, mit rxjs als Observable lösen. Die zeitliche Komponente können wir durch den Producer timer ganz einfach behandeln:
timer(100, 5000).subscribe();
Das Beispiel startet einen periodischen Timer mit einer Anfangsverzögerung von 100 Millisekunden und einem wiederkehrenden Signal alle fünf Sekunden. Ein Synchronisationsdurchlauf könnte durchaus länger als unser Intervall andauern, sodass wir am besten eine Prüfung einbauen, die verhindert, dass wir einen erneuten Vorgang anstoßen, solange der vorherige noch am Arbeiten ist. Das erreichen wir durch den Operator exhaustMap. Er verwirft das äußere Signal, solange dessen inneres Observable noch nicht emittet hat, also vollständig durchlaufen ist:
timer(100, 5000)
.pipe(
exhaustMap(() => /* … */),
)
.subscribe();
Um den API-Endpunkt mit dem Frontend bekannten Timestamp (rowversion) aufrufen zu können, müssen wir diese Information entsprechend vorhalten. Dafür haben wir bereits in der IndexedDb eine zusätzliche Tabelle definiert, die anhand dem Entitätsnamen den letzten Timestamp speichert. Die Abfrage-API von Dexie.js ist Promise-basiert und kann in Observable-Pipes an den meisten Stellen, an denen ein Observable erwartet wird, verwendet werden:
/* … */
.pipe(
exhauseMap(() => this.table('timestamps').where({ name: 'person' }).first()),
)
/* … */
Würden wir auf der gleichen Ebene wie das exhaustMap() weitere Operatoren schreiben, würden wir den gewünschten Effekt verlieren, auf einen vollständigen Durchgang zu warten, bevor weitere Synchronisationssignale verarbeitet werden. Indem wir die Methode per async markieren, können wir innerhalb des Operators die asynchronen Anweisungen linear mit await einbauen. Die Methode gibt dann eine Promise zurück, die auflöst, wenn jeglicher asynchroner Code, auf den mit await gewartet wird, abgelaufen ist:
/* … */
.pipe(
exhauseMap(async () => {
const status = await this.table('timestamps').where({ name: 'person' }).first();
}),
)
/* … */
Wir nehmen den gegebenenfalls vorhandenen Timestamp und nutzen ihn, um bei der API die neusten Änderungen abzufragen. Wir destrukturieren die Property value direkt in eine lokale Variable, um vereinfacht darauf zugreifen zu können. Falls kein bisheriger Eintrag vorliegt, können wir einfach einen leeren Wert übertragen und bekommen dann alle Daten:
/* … */
.pipe(
exhauseMap(async () => {
const { value } = (await this.table('timestamps').where({ name: 'person' }).first()) || { value: '' };
const result = await this.httpClient.get<SyncResult>('sync/person', { params: { timestamp: value }}).toPromise();
}),
)
/* … */
Nach dem Erhalt der Daten sollten wir zuerst die Änderungen in die IndexedDb übertragen. Diese befinden sich in der Antwort der API im Property changed. Auch hier destrukturieren wir gleich in eine lokale Variable. Beim Übertragen in die IndexedDb können wir uns Dank Dexie.js sparen zu prüfen, ob ein Datensatz geändert oder neu angelegt werden muss. Dazu reicht es, die Methode bulkPut() zu nehmen. Diese übernimmt die Prüfung für uns:
/* … */
.pipe(
exhauseMap(async () => {
const timestamp = (await this.table('timestamps').where({ name: 'person' }).first()) || { value: '' };
const { changed } = await this.httpClient.get<SyncResult>('sync/person', { params: { timestamp: timestamp.value }}).toPromise();
await this.table('persons').bulkPut(changed);
}),
)
/* … */
Danach sollten wir die Datensätze löschen, die uns die API in der Property deleted als gelöscht übermittelt hat:
/* … */
.pipe(
exhauseMap(async () => {
const { value } = (await this.table('timestamps').where({ name: 'person' }).first()) || { value: '' };
const { changed, deleted } = await this.httpClient.get<SyncResult>('sync/person', { params: { timestamp: value }}).toPromise();
await this.table('persons').bulkPut(changed);
await this.table('persons').bulkDelete(deleted);
}),
)
/* … */
Als letzte Aktion, die natürlich erst durchgeführt werden darf, wenn das Aktualisieren/Einfügen und Löschen erfolgreich war, müssen wir den neuen Timestamp speichern, um diesen beim nächsten Mal als neuen Wert zur Abfrage verwenden zu können:
/* … */
.pipe(
exhauseMap(async () => {
const { value } = (await this.table('timestamps').where({ name: 'person' }).first()) || { value: '' };
const params = { timestamp: timestamp.value };
const { changed, deleted, timestamp } = await this.httpClient.get<SyncResult>('sync/person', { params: { timestamp: value } }).toPromise();
await this.table('persons').bulkPut(changed);
await this.table('persons').bulkDelete(deleted);
await this.table('timestamps').put({ name: 'person', value: timestamp });
}),
)
/* … */
Mit diesen wenigen Zeilen Code haben wir einen einfachen aber wirkungsvollen Synchronisationsalgorithmus erstellt. Nur würde beim Auftreten eines Fehlers das Observable sich im Moment einfach beenden und die Synchronisation somit stoppen. Ein Fehler könnte zum Beispiel dann auftreten, wenn die Anfrage an die API aufgrund eines Netzwerkverlustes fehlschlägt. Durch das Hinzufügen des retry() Operators können wir dies sehr einfach, aber wirkungsvoll verhindern:
/* … */
.pipe(
exhauseMap(async () => {
/* … */
}),
retry(),
)
/* … */
Abfragen der synchronisierten Daten
Jetzt stehen uns die synchronisierten Daten auf dem Client zur Verfügung und wir können, auch wenn das Gerät offline ist, auf diese zugreifen. Da die jeweiligen Zugriffsmethoden bereits asynchron sind (der Datenzugriff ist ein HTTP-Aufruf), können wir den Inhalt der Methode von einem HTTP-Zugriff zu einem Zugriff auf die IndexedDb umschreiben:
/* … */
getAll(): Promise<Person[]> {
return this.table('persons').toArray();
}
/* … */
Da, wie anfangs erwähnt, in der bisherigen App die Async-Pipe in den Templates verwendet wird, um auf die Daten zu warten, ermöglicht dies uns die folgende (fast geschenkte) Erweiterung:
Bonus: Automatisches Aktualisieren der UI
Wir ändern die Methode von Promise<> zu Observable<>, um immer bei aktualisierten Daten einen erneuten Emit des Observables mit den geänderten Daten zu ermöglichen. Dazu benötigen wir einfach ein Subject<>, das wir in die Pipe des Lade-Observables einbauen – wir nehmen aber explizit ein BehaviourSubject<> um direkt einen ersten Emit beim subscribe() (den die Async-Pipe für uns macht) zu erhalten:
/* … */
private readonly refresh = new BehaviorSubject(null);
/* … */
getAll(): Promise<Person[]> {
return this.refresh
.pipe(
switchMap(() => this.table('persons').toArray()),
);
}
/* … */
Das Signalisieren der Aktualisierung wird dann einfach nach einer erfolgreichen Synchronisation erfolgen:
/* … */
.pipe(
exhauseMap(async () => {
/* … */
await this.table('timestamps').put({ name: 'person', value: timestamp });
this.refresh.next(null);
}),
)
/* … */
Weitere Überlegungen und Herausforderungen
Daten offline anlegen/ändern/löschen
Das Anlegen, Ändern und Löschen von Daten in einem Offlineszenario birgt diverse Hürden, die gemeistert werden müssen. Unter anderem die folgenden Themen:
- Generieren von Primärschlüssel für neue Elemente
- Konfliktsituationen, z.B. dass Daten währenddessen von jemand anderem geändert wurden
Primärschlüssel
Damit ein Client im Offlinezustand Datensätze anlegen und diese in und für weitere Beziehungen verwenden kann, benötigt dieser mindestens die Möglichkeit einen validen Primärschlüssel zu erstellen. Falls der Datensatz bereits einen natürlichen Schlüssel hat, kann auch dieser verwendet werden. Eine drittes Szenario könnte sein, dass der Client einen validen Temporärschlüssel erzeugt, der sich erkennbar von Primärschlüssel unterscheidet, um ihn nach der Übertragung zum Server ersetzen zu können.
Um dem Client die Möglichkeit zu geben, neben einer verlässlichen Library, selbständig Primärschlüssel zu setzen, kann man auch auf dem Server eine gewisse Menge an generierten Schlüsseln erstellen und diese bereits offline vorhalten. Mit diesen kann der Client dann seine neuen Datensätze versehen und sicherstellen, dass es bei der Eindeutigkeit des Schlüssels bleibt, und zusätzlich direkt in jeglichen Beziehungen ohne Probleme verwenden.
Temporärschlüssel wiederum müssen nach der Übertragung zum Server an allen Stellen mit den dann korrekten, vom Server generierten Primärschlüssel ersetzt werden.
Konfliktsituationen
Immer wenn Daten offline geändert werden, gibt es keine Garantie, dass dieser Datensatz nachdem der Client wieder online gegangen ist, auf dem Server noch in dem Zustand ist, als mit der Änderung begonnen wurde – beziehungsweise ob der Datensatz überhaupt noch existiert. Im letzeren Fall kann es, falls ein Datensatz tatsächlich gelöscht wurde (und nicht nur als gelöscht markiert ist), beim Einfügen von Fremdbeziehungen zu relationalen Fehler kommen. Wurde der eigentliche Datensatz „nur“ vom Client geändert, ist die Änderung am Ende ja sowieso hinfällig. Unter Umständen sollte man jedoch den Benutzer trotzdem darüber informieren, dass seine Änderung verfallen ist, da der Datensatz in der Zwischenzeit gelöscht wurde.
Schwieriger wird es, wenn ein anderer Benutzer gleichzeitig denselben Datensatz sogar noch im selben Feld geändert hat. Hier haben wir dann den klassischen Synchronisationskonflikt. Häufig kommt hier gerne die lapidare Entscheidung „Der letzte gewinnt (last one wins)“ zum Tragen, was aber in einem Offlineszenario nicht der letzte Editor sein wird, sondern der Client, der als letztes online ging. Dessen Änderung kann aber schon Tage, Wochen oder noch länger zurückliegen und der Datensatz wurde mittlerweile mehrfach von verschiedenen Benutzern bearbeitet. Und selbst wenn eine Erkennung stattfindet, ob die Änderung in verschiedenen Felder war, kann es dazu führen, dass z.B. unterschiedliche Felder, die logisch zusammengehören, nicht mehr zusammen passen.
Die aufwendigste Herangehensweise an das Thema „Konfliktbehandlung“ ist natürlich die interaktive Auflösung. Dies bedeutet, dass der Benutzer im Falle eines Konfliktes den klassischen Merge durchführen muss, wie man ihn auch von Quellcode-Verwaltungssoftware (z.B. Git) kennt. Die Herausforderung hierbei ist, dies entsprechend visuell darzustellen, um dem Benutzer auch tatsächlich eine Entscheidungsmöglichkeit bieten zu können. Da es am Ende aber sogar um strukturierte Daten gehen kann, ist dies eine wirklich sehr aufwendige Thematik.
Security
Ein sehr interessanter Aspekt ist natürlich das Thema Security. Eine erste Frage, die man sich stellen sollte, ist wann die Offlinedaten wieder gelöscht werden? Es kann nämlich sein, dass wenn der Benutzer sich ausloggen will, lokal geänderte Daten vorliegen die noch nicht synchronisiert sind. Würde man alle offline gespeicherte Daten einfach löschen, wären diese Änderungen unwiederbringlich verloren. Es empfiehlt sich, den Logout dann solange herauszuzögern und den Benutzer darauf hinzuweisen, dass noch Daten zur Synchronisation ausstehen.
Eine noch größere Herausforderung kann aber sein, dass Datensätze „plötzlich“ ohne Änderung an diesen für einen Benutzer sichtbar oder nicht mehr sichtbar werden, nämlich durch Anpassungen in den Berechtigungen. Häufig durch die Änderung von Gruppenzugehörigkeit oder Rechteausweitung, beziehungsweise -reduzierung. Ein möglicher Ansatz, sich dem Problem zu nähern, könnte sein, periodisch das „Universum“ des Benutzers zu prüfen – aber in dem Fall nur die entsprechenden Primärschlüssel. Mit dieser Liste kann dann immer ein Abgleich der Offlinedatensätze erfolgen und fehlende Einträge nachgeladen und nicht mehr sichtbare entsprechend entfernt werden. Je nach Menge der Daten kann es ratsam sein, dies im Bulk zu machen.
Daneben kann auch eine explizite Datenbank bzw. Tabellen für den vorgesehenen Zustand eines Benutzers erstellt werden, die während dem Ermitteln der notwendigen Daten für ein neues Delta immer herangezogen werden. Diese würde dann periodisch aktualisiert und trägt immer die sichtbaren Primärschlüssel für alle zugreifbaren Daten eines Benutzers. Änderungen in dieser Liste sollte man dann einfach per rowversion erkennen. Da aber zwei unterschiedliche Werte für einen Datensatz (aus Sicht des Clients) problematisch sind, sollte die periodische Änderungsprüfung des eigentlichen Datensatzes zentral erfolgen und eine Änderung des oder der Zustandseinträge herbeiführen, um diesen Primärschlüssel in der nächsten Synchronisations-Anfrage zu beachten.
Zusammenfassung
Schlussendlich ist es mit den richtigen Überlegungen nicht so kompliziert, eine Anwendung offlinefähig zu bekommen. Gerade mit Angular, rxjs und Dexie.js hat man mächtige Werkzeuge zur Hand, um dieses Vorhaben umsetzen zu können. Natürlich sollte in der reinen Onlineanwendung eine gute, durchdachte Architektur bereits vorherrschen, um mit wenig Aufwand an den richtigen Stellen die notwendigen Anpassungen vornehmen zu können. Die großen Herausforderungen kommen erst dann, wenn die Daten tatsächlich offline verfügbar sind. Diese nachgelagerten Überlegungen bezüglich lokaler Änderung während der Client offline ist, Konfliktsituationen beim späteren Speichern der geänderten Daten oder die Schlüsselgenerierung bedeuten weitaus mehr Aufwand und Klärungsbedarf als die reine technische Umsetzung.